
ETL com Python na Engenharia de Dados Moderna
No ecossistema de Big Data, o processo de ETL (Extract, Transform, Load) é a espinha dorsal que sustenta a tomada de decisão inteligente. Para um Engenheiro de Dados, dominar o ETL utilizando Python não é apenas uma preferência técnica, mas uma necessidade estratégica devido à versatilidade e à vasta biblioteca da linguagem.
O Fluxo do ETL: Da Origem ao Valor
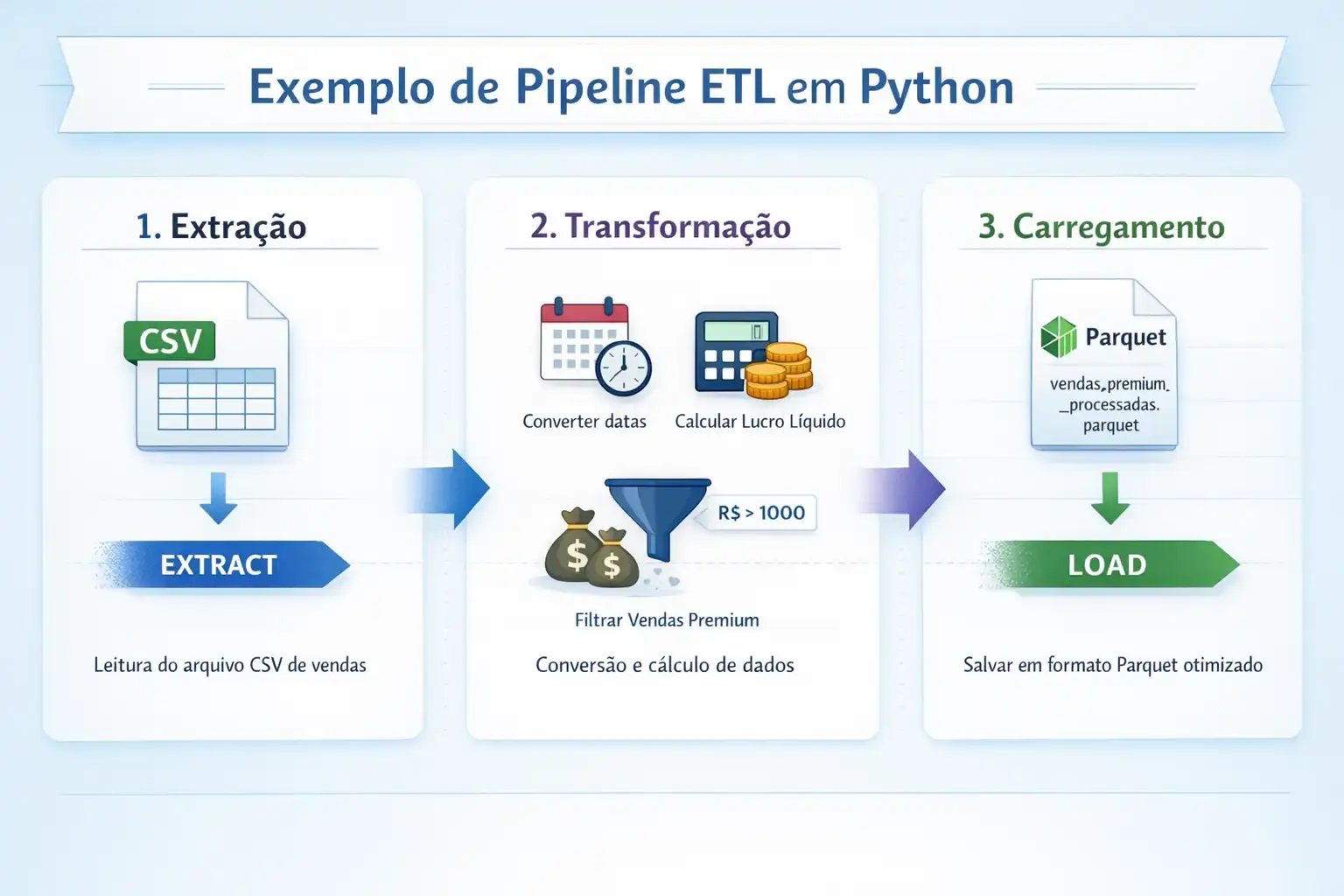
O ETL consiste em três etapas fundamentais que transformam dados brutos em ativos de negócio:
- Extração (Extract): Coleta de dados de fontes heterogêneas, como APIs, bancos de dados SQL/NoSQL, arquivos CSV ou logs de servidores.
- Transformação (Transform): A fase mais crítica, onde os dados são limpos, normalizados e enriquecidos. É aqui que as regras de negócio são aplicadas.
- Carregamento (Load): O envio dos dados processados para um destino final, geralmente um Data Warehouse ou um Data Lake.
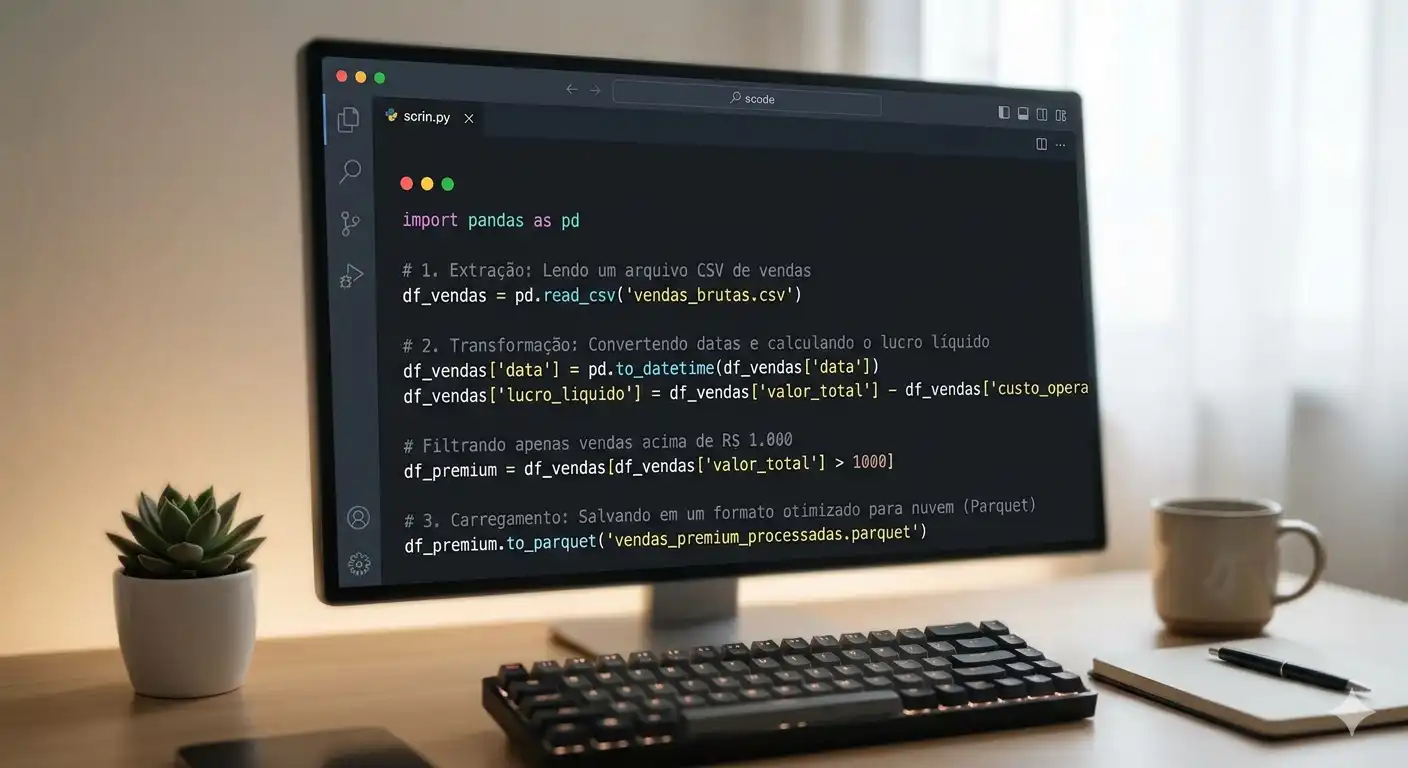
Exemplo Prático: ETL Simples em Python
Python brilha na manipulação de dados graças a bibliotecas como Pandas. Abaixo, um exemplo simplificado de como processar dados de vendas:
Aplicações de Negócio
O ETL não vive apenas no código; ele resolve dores reais das empresas:
- Varejo: Consolidar dados de lojas físicas e e-commerce para entender o comportamento omnicanal do cliente.
- Finanças: Unificar registros de transações de diferentes moedas e aplicar taxas de câmbio em tempo real para relatórios de conformidade.
- Saúde: Cruzar dados de prontuários com resultados laboratoriais para prever surtos de doenças ou otimizar a ocupação hospitalar.
O Reflexo na Nuvem e Escalabilidade
Na Engenharia de Dados moderna, o Python raramente opera sozinho em uma máquina local. O verdadeiro impacto do ETL é sentido quando integrado a provedores de nuvem (AWS, Azure, Google Cloud):
- Serverless Computing: Scripts Python podem ser executados no AWS Lambda ou Google Cloud Functions para processar arquivos assim que eles chegam ao storage.
- Processamento Distribuído: Quando o volume de dados ultrapassa os Gigabytes, o Engenheiro de Dados utiliza o PySpark no Amazon EMR ou Azure Databricks, permitindo que o ETL seja processado em clusters de máquinas simultaneamente.
- Orquestração: Ferramentas como o Apache Airflow (baseado em Python) gerenciam a ordem e a frequência dessas tarefas, garantindo que o dado chegue ao dashboard do CEO todas as manhãs sem falhas.
Impacto Estratégico
- Eficiência operacional: menos desperdício e maior produtividade.
- Decisão em tempo real: dashboards alimentados por pipelines ETL permitem ajustes imediatos.
- Competitividade: empresas que usam ETL conseguem responder mais rápido às mudanças de mercado e demandas dos clientes.


