🧠 Entendendo as Camadas de Atenção no Machine Learning
Se você já se perguntou como um modelo consegue “prestar atenção” nas palavras certas de uma frase, bem-vindo ao mundo das Attention Layers! 🤖✨
As camadas de atenção surgiram como uma forma de melhorar o desempenho de redes neurais, especialmente nas tarefas de tradução automática, resumo de textos, classificação de sentimentos e muito mais.
🔍 O que é Atenção?
A ideia principal é simples (e genial): dar pesos diferentes para cada parte da entrada, dependendo da sua importância para a tarefa. É como se o modelo perguntasse:
-“Em que parte da frase eu deveria focar para prever a próxima palavra?”
🧩 Tipos de Atenção:
- Self-Attention: cada palavra olha para todas as outras da frase (inclusive ela mesma). Usado no Transformer.
- Multi-Head Attention: várias “atenções” paralelas, capturando diferentes aspectos do contexto.
- Cross-Attention: uma sequência presta atenção em outra (ex: entrada vs. saída no Transformer Encoder-Decoder).
💥 Por que é importante?
Antes das camadas de atenção, modelos tinham dificuldade em entender dependências longas. Com atenção, conseguimos:
- ✔Compreender contexto
- ✔Capturar relações complexas
- ✔Aumentar performance com menos custo computacional
🧠 Resumo Visual da Self-Attention (modo texto 😄):
Palavra 1 ➡️ olha para ➡️ todas as palavras da frase
Palavra 2 ➡️ idem
...
Cada palavra ➡️ recebe uma pontuação de “atenção” baseada em similaridade
🚀 Curiosidade
Modelos como BERT, GPT, T5 e até o ChatGPT usam atenção como base! 💡
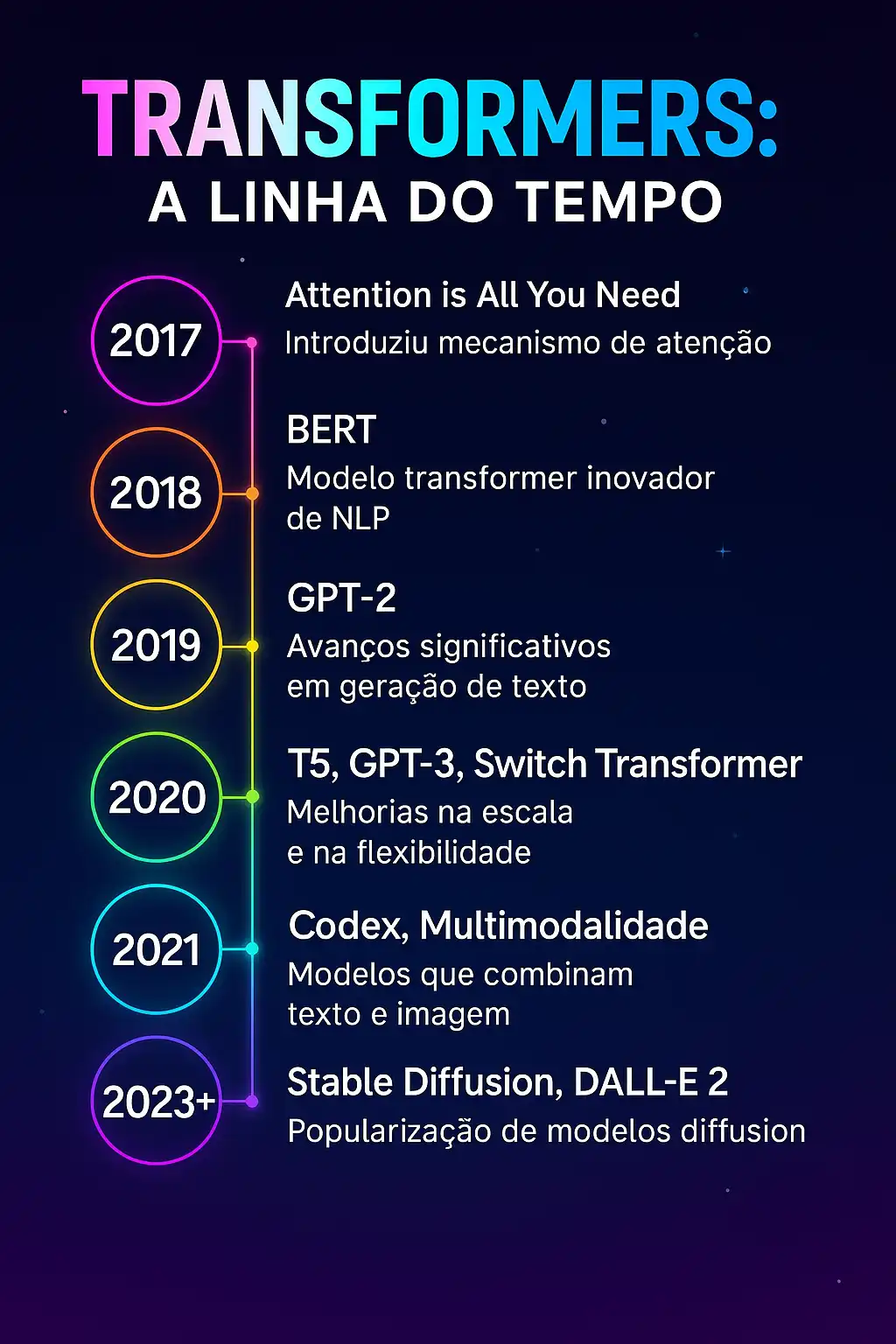
Abaixo, linha do tempo Transformers: