
WEBthrough - Um passeio pela web
- #GoLang
MOTIVAÇÃO
Antes de você se enfiar no código eu gostaria de explicar um pouco do porquê fiz esse projeto.
O Github é um lugar gigantesco e uma coisa que eu costumava fazer é entrar aqui olhar apenas meus próprios repositórios, atualizar meus projetos e sair e a vantagem de ter acesso ao Github na verdade não está em nós e sim nos outros. Aqui temos acesso ao código não apenas de outros desenvolvedores mas também de organizações e estar assim tão perto do código da equipe do Kubernetes, Google, das guidelines de javascript do Airbnb, guidelines de API da Microsoft e não fazer proveito disso é quase um crime!
A ideia toda desse repositório é que você aprenda não apenas como funciona a web, mas a como ler código de outras pessoas e organizações no Github, de uma forma eficiente e tornar isso um hábito.
E porque você gostaria de tornar isso um hábito?
Ler código de outras pessoas irá te expor a diferentes práticas, tanto as boas quanto as ruins e com isso você irá exercitar uma das habilidades mais importantes para um desenvolvedor que é saber diferenciar código bom, de código ruim.
Esse aqui é um pouco ambicioso mas acho que a gente consegue. Apesar desse ser um tutorial tenho o objetivo de fazer você se livrar da dependência de ter que acompanhar tutoriais em video ou artigos, onde o interlocutor se propõe a explicar o código dela para você durante o processo. Se ela está te explicando, você já sabe o que o código faz, e se você já sabe você não lê, o que te torna completamente refém do interlocutor. Quando na verdade você deveria ler o código antes, anotar o que entendeu e ai sim acompanhar o tutorial para saber se entendeu completamente o que era proposto e assim saber quais os pontos deveria melhorar.
Eu entendo que muitas pessoas gostam ou preferem acompanhar tutoriais através de video, porque precisam de uma coisa que seja menos impessoal.
Relevando isso, quanto tempo você levaria para ler um arquivo de código com 100 linhas em média? Eu não sei e também não vou fazer uma média de tempo pois sei que todas as pessoas tem o seu ritmo.
Em média um tutorial bem explicado sobre como criar um CRUD tem 44min a 60min no youtube. Eu não sei você mas quando eu acompanho esse tipo de tutorial eu costumo escrever o código junto com a pessoa, tem pessoas que preferem ver tudo e depois copiar o código depende.
Mas pensando aqui, se você apenas assistisse os 50min de explicação será que você terminaria de ler em menos tempo do que vendo o video? Provavelmente você levaria mais tempo lendo pois precisaria consultar a documentação. Mas comparar o tempo de leitura e pesquisa com o de assistir ao video + pausas + escrever o código, você terminaria muito mais rápido lendo e ainda teria uma bagagem semelhante a de quem produziu o video. Pois adivinha de onde ele tirou isso tudo? Da documentação.
O que não faltam são tutoriais de todo, CRUD e etc mas as vezes você quer se arriscar e tentam algo diferente. Mas você não conseguiu achar em português ou mesmo em inglês um tutorial decente de como implementar um client de torrent para entender o protocolo P2P. Então você teve a ideia de procurar no Github, tão boa ideia que deveria ter sido a primeira.
Mas quando você encontra o repositório acaba ficando com medo, porque o projeto já foi terminado e agora ele tem 12 arquivos cada um com mais de 200 linhas de código ele já é um obelisco e você se sente intimidado em não saber por onde começar.
Começa pelos commits! Todo projeto que hoje é um monolito colossal já foi um grão de areia perdido na praia de repositórios do Github. Poético.
Acompanhando cada branch, cada commit feito lá no inicio do projeto você sabe onde ele começa e onde ele termina e você saberá também como ele pode ir além. Então apesar desse ser um tutorial para iniciantes a pretensão é de que você consiga criar o hábito de ler mais código e não de apenas produzir.
Porque você leria um artigo sobre boas práticas de software do Google no medium feito pelo darkmage1337 quando você pode entrar em repositório do Google no Github e ver com seus próprio olhos?
COMO FUNCIONA
O processo é feito para que você acompanhe a criação de uma aplicação web usando Golang e seus pacotes da biblioteca padrão.
E porque não iniciamos a introdução a Web com um framework MVC por exemplo? Frameworks são um nível de abstração tão alto que você acaba ficando longe dos conceitos da web e da aplicação a ponto de você fazer poucas tarefas e deixa todo o trabalho debaixo dos panos. Você não precisa ir até o porão da documentação, mas ter a base é essencial, os frameworks fazem utilização da biblioteca padrão para implementar a maior parte da aplicação, então você só está delegando as coisas.
"Você não precisa saber como funciona o motor de um carro para dirigir, mas se você não sabe o que é um carro, provavelmente você não deveria estar dirigindo."
Logo abaixo tem um índice com os assuntos a serem tratados no tutorial, hora esse índice te leva para um commit, outrora para um conteúdo teórico presente aqui no README.md o conteúdo teórico pode ser lido na integra ou você pode ir lendo de acordo com o andamento projeto.
Já os commits vão funcionar da seguinte maneira, cada commit terá uma parte em código para a evolução da aplicação e outra parte em comentários feitas no pŕoprio arquivo .go, até aqui nada demais, porém no próximo commit a aplicação é modificada.
Vamos entender melhor a página de um commit:

Bem no topo da Imagem tem a mensagem de commit "Definindo o inicio do arquivo go"
Em seguida logo após a data do commit temos:
Showing 1 changed file with 8 additions and 0 deletions.
Então cada commit terá o padrão de
Quantos arquivos foram modificados, quantas adições temos, nesse caso ele diz 8 pois se você olhar as linhas do arquivo verá que tem 8 linhas em verde simbolizando o que foi adicionado e 0 deletions que são as linhas apagadas.
Abaixo um novo commit de exemplo, temos esses quadradinhos em verde e vermelho mostrando:
linhas modificadas[79 changes]
linhas adicionadas[48 additions]
linhas deletadas[31 deletions]

Entender isso é primordial para compreender esse tutorial e ler commits de outros projetos.
Em um arquivo onde temos linhas em verde são as linhas adicionadas nesse commit e são onde os seus olhos deveriam se voltar primeiramente. As linhas vermelhas são coisas que foram apagadas e se foram apagadas não nos servem mais então você não deveria voltar sua atenção para elas na maioria do tempo.
O unico momento em que as linhas vermelhas são importantes é quando há uma alteração, nesse caso algo foi apagado e substituído por algo diferente.
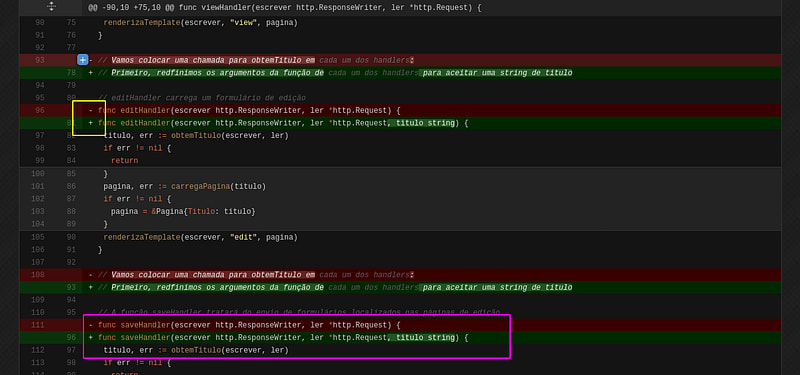
Nessa nova imagem usei o quadrado amarelo para mostrar como visualmente o Github mostra que quando temos o sinal de + temos uma linha verde uma linha adicionada quando temos um sinal de - temos uma linha removida.
Com o retângulo rosa demarquei uma função que foi alterada temos duas linhas praticamente iguais, uma vermelha representando a antiga uma verde representando a nova com um ressalto para a nova que tem uma parte dela em relevo.

Mais de perto é possível verificar que na segunda linha em relevo mostra que a mesma função tem agora um novo argumento que é uma string chamada titulo.
E será assim que você irá ler os commits, o que estiver verde eu leio, em vermelho ignoro pois o que está em vermelho eu já li no commit anterior. Repare que o código também possuí comentários e cada comentário explica o que a nova função sendo adicionada faz.

Como essa é a primeira de muitas vezes que você irá ler commits, dei uma facilitada pra você aqui no começo onde cada commit terá comentários específicos de acordo com o contexto do seu commit.
Mais abaixo você poderá seguir com o índice, caso tenha alguma dificuldade durante o tutorial você pode me chamar no tweet se quiser. vapordev
MINI DISCLAIMER
Você já deve ter percebido que tem algumas coisas no código estão em português decidi que seria assim pois para iniciantes seria mais simples e mais acessível se você acha cringe e prefere em inglês faz em inglês aí da sua casa.

PA GRINGO É MAIS CARO!
COMO A WEB FUNCIONA
Antes da web funcionar temos que saber que a internet é o que faz a web possível. A internet funciona através de uma rede de computadores, se eu tenho um wifi na minha casa e conecto 4 celulares dois notebooks e uma TV eu tenho uma rede de dispositivos conectadas a internet. Então a internet é basicamente isso, uma rede de dispositivos computacionais conectados só que em uma escala global, muita infraestrutura e roteadores melhores.
Agora que eu estraguei todo o glamour dizendo que a internet é um monte de TP-link ligado um no outro, ta na hora de estraga a web. Com essa rede www "world wide web" você tem acesso a diversos dispositivos que estão conectados na infraestrutura da internet. Então através dessa rede temos facilidade de acesso a documentos, livros, vídeos e tudo que podemos hoje encaixar como mídias digitais.
Se eu preciso acessar um video que está dentro do meu computador eu preciso navegar entre as pastas (diretórios) até chegar onde está o meu arquivo e executá-lo. Com a web é bem parecido, você faz um caminho dentro do computador de outra pessoa acessando os domínios, é uma convenção o primeiro domínio de um site em uma rede ser "home" e a home é como se fosse o desktop do do site é nela que você inicia e nela que você encontra os caminhos relativos para onde você pode ou deseja ir.
Se logo após entrar em um site eu estou na endereço/home e quero ir para o arquivo de contato eu irei para endereço/contato porque um site ele é o mesmo que um diretório no seu computador. Então é como se eu estivesse dentro de uma pasta chamada endereço e dentro dela eu tivesse dois arquivos chamados home e contato. Simples assim.
Aplicando a mesma lógica que você usa para criar pastas no seu computador você usa isso para entender websites. A grande diferença é que para você abrir um arquivo de video no computador que está lá do outro lado você precisa se identificar e e ter permissão para acessar esse video, mais a frente falaremos e como aplicações web se comunicam através da internet.
DEFININDO O INICIO DO ARQUIVO GO
Apesar do projeto ser em Golang todas as linguagens modernas possuem pacotes e bibliotecas que permitem a construção de aplicações web sem qualquer auxilio de um framework então esse passo a passo pode ser feito em outras linguagens e eu inclusive recomendo pois torna o processo de aprendizado da linguagem mais desafiador.
Para aqueles que irão fazer o projeto em Golang é assumido que você conhece os fundamentos da linguagem e da organização do GOPATH.
Caso ainda não conheça os fundamentos da programação em qualquer outra linguagem, desencorajo totalmente o pulo de etapas do seu aprendizado. Vou deixar alguns recursos para o aprendizado dos fundamentos em Golang e o convido a voltar com a bagagem necessária para esse tutorial.
Português:
Aprenda Go - Ellen Körbes [Vídeo]
Go por Exemplo - Comunidade [Leitura]
Inglês:
Effective Go - Documentação [Leitura]
Golang intro - sentdex [Vídeo]
Comece criando uma pasta no seu local de trabalho caso seja outra linguagem, caso esteja usando Golang você já sabe onde a pasta deve ficar...
Eu dei o nome de gowiki seguindo o mesmo nome dado no tutorial na documentação de onde veio esse código, mas você pode escolher o nome que achar melhor, em seguida criei o arquivo wiki.go que é onde vai ficar nosso código.
Na linguagem Go, a declaração do package está sempre presente no início do arquivo o objetivo desta declaração é determinar o identificador padrão para aquele package quando ele é importado por outro pacote. Por isso: Package Main
Na linguagem Go, o package main é um package especial que é usado com os programas que são executáveis e este package contém a func main() .A func main() é um tipo especial de função e é o ponto de entrada dos programas executáveis. Não leva nenhum argumento nem retorna nada. Go chama a func main() automaticamente, portanto, não há necessidade de chamar a func main() explicitamente e todo programa executável deve conter um único package main e func main().
ESTRUTURA DE DADOS
Calma, o tópico aqui não será sobre arvoes binárias ou pilhas. Uma struct em Golang é um tipo definido pelo usuário que permite agrupar/combinar itens de tipos possivelmente diferentes em um único type. Qualquer entidade do mundo real que tenha algum conjunto de propriedades/campos pode ser representada como uma struct. Este conceito é geralmente comparado com as classes de programação orientada a objetos. Pode ser denominado como uma classe leve que não oferece suporte a herança, mas oferece suporte à composição.
Sobre a diferença de structs e classes. - StackOverflow
PERSISTÊNCIA
Falando de web não basta apenas ter a estrutura para criar dados, precisamos salvá-los para que um usuário em um momento "A" crie seus dados e no momento "B" quando acessar a aplicação tenha os mesmos dados disponíveis.
Em ciência da computação, persistência se refere à característica de um estado que sobrevive ao processo que o criou. Sem essa capacidade, o estado só existiria na RAM, e seria perdido quando a RAM parasse (desligando-se o computador por exemplo). Wiki
Aqui usamos uma método em Golang para salvar os dados. Os métodos Go são semelhantes à funções com uma diferença, o método contém um argumento receiver. Com a ajuda do argumento do receiver, o método pode acessar as propriedades do receiver. Aqui, o receiver pode ser do tipo de struct ou não. Quando você cria um método em seu código, o receiver e o tipo do receiver devem estar no mesmo package. E você não tem permissão para criar um método no qual o tipo de receiver já está definido em outro package, incluindo inbuilt types como int, string, etc. Se você tentar fazer isso, o compilador apresentará um erro.
Também importamos o pacote io/ioutil
LENDO ARQUIVOS E TRATANDO ERROS
Para ler o arquivo usamos o mesmo pacote ioutil a diferença é que aqui começamos um pouco do processo de tratamento de erros em Go.
Muitas das funções em Go retornam um valor do tipo err, você pode usar o _ undescore para negar os valores de retorno de uma função que retorna um erro o que não é uma boa prática, ou você pode tratar esses valores de erro.
type error interface {
Error() string
}
O tipo error em Go é uma Interface e o zero value de interfaces em go é nil, logo se err for diferente de nil quer dizer que a função retorna a função Error() que retorna uma string. Então tratamento mais simples de erros em go é checar condicionalmente se a função retorna err, e se retornar demonstra a string desse erro.
Nesse caso estamos criando uma função então ela não necessariamente retorna um erro por padrão, mas nessa implementação decidimos que sim.
CHAMANDO AS FUNÇÕES E EXECUTANDO NOSSO CÓDIGO GO
Agora com as funções de salvar e carregar pagina criadas você já consegue criar arquivos baseados em .txt com title e body
Se você apenas copiou o código deve ter notado que o build não funcionou pois o titulo da página não está correto conforme o print.

Na variável escrever eu passei como parâmetro "PaginaTeste" e na variável ler passei "Pagina teste" as vezes corrigindo essa gafe você já pode buildar seu código novamente. Isso não foi uma pegadinha mas quem se alguém travar aqui eu já sei o problema. Aqui importamos o pacote fmt para ter acesso a funções básicas de saída de dados.
APRESENTANDO NET HTTP HANDLER
Agora criamos uma nova pasta pois vamos ter uma breve introdução ao http que é a forma como browsers e aplicações trocam ideia através da internet. Dentro dessa nova pasta chamada net_http criamos um arquivo example.go com as definições de servidor web. Vamos aproveitar agora para saber um pouco mais sobre o que é http.
HYPERTEXT TRANSFER PROTOCOL HTTP SEMÂNTICA E CONTEXTUAL
O protocolo de transferência de hipertexto (HTTP) é uma aplicação stateless para sistemas distribuídos, colaborativos e de hipertexto.
Cada mensagem de protocolo HTTP é uma requisição ou uma resposta.
Um servidor escuta em uma conexão esperando uma requisição, analisa cada mensagem recebida, interpreta a semântica da mensagem em relação ao destino da requisição identificada e responde a essa requisição com uma ou mais mensagens de resposta.
Um client constrói mensagens de requisição para comunicar intenções específicas, examina as respostas recebidas para ver se as intenções foram realizadas e determina como interpretar os resultados.
RESOURCES
O destino de uma requisição HTTP é chamado de "resource" ou em português recurso. O HTTP não limita a natureza de um resource; apenas define uma interface que pode ser usada para interagir com resources.
Cada resource é identificado por um Uniform Resource Identifier (URI). Quando um client constrói uma mensagem de requisição HTTP / 1.1, ele envia o URI de destino em uma das várias formas.
- Request Target
- origin-form
- absolute-form
A forma mais comum de requisição de destino é o origin-form.
origin-form = absolute-path ["?" query ]
Ao fazer uma requisição diretamente a um servidor, diferente de um CONNECT ou server-wide OPTIONS (conforme detalhado abaixo), um client DEVE enviar apenas o absolute-path e os componentes de query (consulta) do destino URI como destino da requisição.
Se o componente do caminho do URI de for vazio, o client DEVE enviar "/" como o caminho dentro do formulário de origin-form.
Por exemplo, um client que deseja recuperar uma representação do
resource identificado como
http://www.example.org/where?q=now
diretamente do servidor abriria (ou reutilizaria) uma conexão TCP à porta 80 do host "www.example.org" e envie as linhas:
GET /where?Q=now HTTP/1.1
Host: www.example.org
Seguido pelo restante da mensagem de requisição.
APRESENTANDO NET HTTP LISTENANDSERVE
Além do net/http importamos também o pacote log que define um tipo, Logger, com métodos para formatar o output. Esse logger grava no standard error e imprime a data e hora de cada mensagem registrada. As funções Fatal chamam os.Exit(1) depois de escrever a mensagem de log.
os.Exit faz com que o programa atual saia com o código de status fornecido. Convencionalmente, o código zero indica sucesso, diferente de zero um erro.
E ListenAndServe que por sua vez está envolvido por essas funções. É preciso ter o conhecimento teórico sobre como funciona a web e o protocolo http pois assim cada função desse pacote fará mais sentido pra você.
USANDO NET HTTP PARA SERVIR WIKI.GO VIEWHANDLER
Agora que já testamos o pacote http e já entendemos como servir uma aplicação em uma porta na web, podemos apagar a pasta onde o exemplo estava e voltar a nossa atenção a wiki.go e criar uma viewHandler o conceito de view é muito conhecido em padrões de arquitetura MVC mas não falaremos disso pelo menos por enquanto, basta saber que a view se trata do que ficará acessível visualmente para um browser.
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
Então quando eu tenho um servidor na porta 8080 e quero prover informações nesse endereço eu uso o ler(*Request) que vai me dar o estado do resource e escrever(ResponseWriter) que vai escrever no servidor que eu levantei os dados providos em uma página HTML.
REQUEST METHODS
Os request methods são a fonte primária de requisição semântica; indica a finalidade para a qual o client fez a requisição e o que o client espera como resultado.
A semântica dos request methods podem ser ainda mais especializadas pela semântica de alguns campos de Header, quando presentes em uma requisição.
Por exemplo, um client pode enviar campos de Header de requisição condicional para tornar a ação solicitada condicional ao atual estado do resource.
method = token
HTTP foi originalmente projetado para ser usado como uma interface para sistemas de objetos distribuídos.
O request methods foi concebido aplicando semântica a um resource da mesma maneira que invocar um método definido em um objeto identificado onde semântica seria aplicável.
O token do método case-sensitive porque pode ser usado como um gateway para sistemas baseados em objetos com método case-sensitive.
Ao contrário dos objetos distribuídos, os request methods padronizados em HTTP não são específicos de resources, uma vez que interfaces uniformes fornecem melhor visibilidade e reutilização em sistemas baseados em rede REST ].
Uma vez definido, um método padronizado deve ter a mesma semântica quando aplicado a qualquer resource, embora cada resource determine por si mesmo se essas semânticas são implementadas ou permitidas.
HEAD
O método HEAD é idêntico ao GET, exceto que o servidor NÃO DEVE enviar uma mensagem no corpo da resposta (ou seja, a resposta termina no final da seção do head).
O servidor DEVE enviar os mesmos campos de head em resposta a uma requisição HEAD como teria enviado se o pedido tivesse sido um GET, exceto que os campos de header de payload PODEM ser omitidos.
Este método pode ser usado para obter metadados sobre a representação selecionada sem transferir os dados de representação e é frequentemente usado para testar links de hipertexto para validade, acessibilidade e modificação recente.
Um payload em uma mensagem de requisição HEAD não tem semântica definida; enviar um body payload em uma requisição HEAD pode fazer com que algumas implementações existentes rejeitem a requisição.
Sintaxe
HEAD /index.html
USANDO NET HTTP PARA SERVIR WIKIGO HANDLEFUNC
Toda função de Handler que trata uma request e uma response é manipulada por uma handleFunc na chamada de main.
GET
O método GET requisita a transferência de uma representação atual selecionada para o resource de destino.
GET é o principal mecanismo de informação recuperação e o foco de quase todas as otimizações de desempenho.
Portanto, quando as pessoas falam em recuperar algumas informações identificáveis via HTTP, eles geralmente se referem a fazer uma requisição GET.
Sintaxe
GET /index.html
EDITANDO PÁGINAS WIKIGO EDITHANDLER
Aqui temos a criação de um novo handler agora fazendo uso da nossa função customizada carrega página.
POST
O método POST requisita que o resource processe a representação incluída na requisição de acordo com sua própria semântica específica. Por exemplo, POST é usado para o seguinte funções (entre outras):
- Fornecendo um bloco de dados, como campos inseridos em um formulário HTML, para um processo de tratamento de dados;
- Publicar uma mensagem em um quadro de avisos, grupo de notícias, lista de e-mails, blog ou grupo de artigos;
- Criação de um novo resource que ainda não foi identificado pelo
- servidor;
- Anexar dados à representações existentes de um resource.
O servidor indica a semântica de resposta escolhendo um código de status apropriado, dependendo do resultado do processamento da requisição POST; quase todos os códigos de status definidos pela especificação pode ser recebida em uma resposta ao POST (as exceções sendo 206 (Partial Content), 304 (Not Modified) e 416 (Not Modified)).
Se um ou mais resources foram criados no servidor como um resultado do processamento bem-sucedido de uma requisição POST, o servidor DEVE enviar uma resposta 201 (Created) contendo um header de localização que fornece um identificador para o resource primário criado.
Se o resultado do processamento de um POST seria equivalente a um representação de um resource existente, o servidor PODE redirecionar o user agent para esse resource, enviando uma resposta 303 (See Other) com o identificador do resource existente no campo Localização.
Sintaxe
POST /test
Exemplo
POST /test HTTP/1.1Host: foo.exampleContent-Type: application/x-www-form-urlencodedContent-Length: 27field1=value1&field2=value2
PUT
O método PUT requisita que o estado do resource seja criado ou substituído pelo estado definido pela representação incluída no payload da mensagem de requisição. Um PUT bem-sucedido de uma determinada representação sugere que um GET subsequente no mesmo resource resultará no envio de uma representação equivalente em uma resposta 200 (OK).
No entanto, não há garantia de que tal mudança de estado será observável, uma vez que o resource pode ser acionado por outros user agents em paralelo, ou pode estar sujeito a processamento dinâmico pelo servidor, antes que qualquer GET subsequente seja recebido. Uma resposta bem-sucedida implica apenas que a intenção do user agent foi alcançada no momento de seu processamento pelo servidor.
Se o resource não tiver uma representação atual e o PUT criar um com sucesso, então o servidor DEVE informar o user agent enviando uma resposta 201 (Criado).
Se o resource tem uma representação atual e essa representação for modificada com êxito, então o servidor DEVE enviar uma resposta 200 (OK) ou 204 (No Content) para indicar a conclusão bem-sucedida da requisição.
Um servidor DEVE ignorar campos de header não reconhecidos recebidos em uma requisição PUT (ou seja, não os salve como parte do estado do resource). Um servidor DEVE verificar se a representação PUT é consistente com quaisquer restrições que o servidor tenha para o resource que não pode ou não será alterado pelo PUT.
Isso é particularmente importante quando o servidor usa informações de configuração interna relacionadas ao URI para definir valores para metadados em respostas GET.
Quando uma representação PUT é inconsistente com o resource, o servidor DEVE torná-los consistentes, transformando a representação ou alterando a configuração do resource, ou responder com uma mensagem de erro apropriada contendo informações suficientes para explicar por que a representação é inadequada.
O Status Code 409 (Conflict) ou 415 (Unsupported Media Type) são sugeridos, com o último sendo específico para restrições nos valores de Content-Type. Por exemplo, se o resource está configurado para sempre ter um Content-Type de "text/html" e a representação PUT tem um Content-Type de "imagem/jpeg", o servidor deve fazer um dos seguintes:
a. reconfigure o resource para refletir o novo tipo de mídia;
b. transformar a representação PUT em um formato consistente com o do resource antes de salvá-la como o novo estado do resource; ou
c. rejeitar a requisição com uma resposta 415 (Unsupported Media Type) indicando que o resource está limitado a "text/html", talvez incluindo um link para um resource diferente que seria um destino adequado para a nova representação.
Sintaxe
PUT /new.html HTTP/1.1
Exemplo
- Requisição
PUT /new.html HTTP/1.1Host: example.comContent-type: text/htmlContent-length: 16<p>New File</p>
- Resposta
HTTP/1.1 201 CreatedContent-Location: /new.html
PATCH
O método PATCH é utilizado para aplicar modificações parciais em um resource.
Sintaxe
PATCH /file.txt HTTP/1.1
Exemplo
- Requisição
PATCH /file.txt HTTP/1.1 Host: www.example.comContent-Type: application/exampleIf-Match: "e0023aa4e"Content-Length: 100[description of changes]
- Resposta
No exemplo abaixo, um código 204 de resposta é usado, porque a resposta não carrega um body. Uma resposta 200 pode conter um body payload.
HTTP/1.1 204 No ContentContent-Location: /file.txtETag: "e0023aa4f"
HTML TEMPLATE SEPARANDO O HTML DO CÓDIGO GO
Até então tínhamos utilizado as funções de Fprint do pacote fmt para enviar a saída de dados em html, porém ter o código html assim misturado com o código Golang torna as coisas bem mais complexas, o template fornece uma forma de parsear arquivos html no código Golang.
Eu já havia usado o erb.html antes com o Rails onde você embedava o Ruby no html com as tags <%= %> depois de um tempo você acaba se acostumando. Mas o que eu vi sobre html com Golang fez com que eu gostasse ainda mais, o html não muda a extensão e ao invés de você deixar o html envolto em código na verdade você envolve código Go em html. Acho que isso ajuda a manter as pessoas que vem do front end um pouco mais tranquilas.
A partir daqui iremos trabalhar com html, não subestimar o poder da hyper text markup language pois ele é muito poderoso.
Tutorial de HTML - w3schools [Leitura]
APLICANDO TEMPLATE NA VIEW
Como nesse commit a gente só refatora mais coisa eu vou aproveitar pra te mostrar mais alguns métodos http que ainda não mostrei.
CONNECT
O método CONNECT estabelece um túnel para o servidor identificado pelo resource.
Sintaxe
CONNECT www.example.com:443 HTTP/1.1
Exemplo
CONNECT server.example.com:80 HTTP/1.1 Host: server.example.com:80 Proxy-Authorization: basic aGVsbG86d29ybGQ=
TRACE
O método TRACE executa um teste de chamada loop-back junto com o caminho para o resource.
Sintaxe
TRACE /index.html
OPTIONS
O método OPTIONS é usado para descrever as opções de comunicação com o resource.
Sintaxe
OPTIONS /index.html HTTP/1.1
OPTIONS * HTTP/1.1
Exemplo
Para descobrir quais métodos de requisição um servidor suporta, pode-se usar o curl para enviar uma requisição OPTIONS:
curl -X OPTIONS http://example.org -i
- Resposta
HTTP/1.1 204 No ContentAllow: OPTIONS, GET, HEAD, POSTCache-Control: max-age=604800Date: Thu, 13 Oct 2016 11:45:00 GMTExpires: Thu, 20 Oct 2016 11:45:00 GMTServer: EOS (lax004/2813)x-ec-custom-error: 1
DIMINUIÇÃO DA REDUNDÂNCIA ISOLANDO A FUNÇÃO TEMPLATE
Começamos então a customizar uma função de renderização para que não tenhamos que implementar a mesma em todos os Handlers, imagine que você tem 30 Handlers, não seria assim tão produtivo.
Portando é mais fácil customizar a função e fazer uma chamada em cada Handler.
E agora com vocês mais um método http.
DELETE
O método DELETE requisita que o servidor remova a associação entre o resource e sua atual funcionalidade. Na verdade, este método é semelhante ao comando rm no UNIX: expressa uma operação de exclusão no mapeamento de URI do servidor.
Se o resource tiver uma ou mais representações atuais, ele pode ou não ser destruído pelo servidor, e o armazenamento associado pode ou não ser recuperado, dependendo inteiramente da natureza do resource e sua implementação pelo servidor.
Da mesma forma, outros aspectos de implementação de um resource podem ser desativados ou arquivados como resultado de um DELETE, como banco de dados ou conexões de gateway. Em geral, presume-se que o servidor só permitirá DELETE em resources para os quais ele tem um mecanismo prescrito para realizar a exclusão.
Relativamente poucos resources permitem o método DELETE - seu uso principal é para ambientes de autoria remotos, onde o usuário tem alguma direção quanto ao seu efeito. Por exemplo, um resource que foi criado anteriormente usando uma requisição PUT ou identificado por meio do header após uma resposta 201 (Created) em resposta a um POST, pode permitir que um pedido DELETE desfaça aquelas ações.
Da mesma forma, as implementações de user agent personalizado que implementam uma função de autoria, como clients de controle de revisão usando HTTP para operações remotas, podem usar DELETE com base na suposição de que o espaço URI do servidor foi criado para corresponder a uma versão de repositório.
Se um método DELETE for aplicado com sucesso, o servidor DEVE enviar um status code 202 (Accepted) se a ação provavelmente terá êxito mas ainda não foi aprovada, um status code 204 (Not Content) se a ação foi decretada e nenhuma informação adicional foi fornecida ou um status code 200 (OK) se a ação foi decretada e o a mensagem de resposta inclui uma representação que descreve o status.
Um payload em uma mensagem de requisição DELETE não tem semântica definida; enviar um corpo de payload em uma requisição DELETE pode fazer algumas implementações rejeitar o pedido.
Sintaxe
DELETE /file.html HTTP/1.1
MANIPULAÇÃO DE PÁGINAS INEXISTENTES
Depois de fazer um ou dois Handlers a forma como as páginas, requisições e respostam começam a se tornar conceitos mais simples para nós e tudo que precisamos fazer é aplicar pŕaticas que tornam nossa aplicação mais robusta e menos suscetível a erros.
Temos uma nova função "redirect" que entrega de bandeja o motivo da sua existência, ela retorna um valor http.StatusFound.
Em Golang http.StatusFound é uma de várias constantes no pacote http no caso ela representa o inteiro 302.
Found na resposta de uma requisição significa que o resource reside temporariamente em uma outra URI. O server envia uma resposta para o header com o campo Location para que haja um redirecionamento automático.
SALVANDO PÁGINAS
Finalmente salvando os dados e nesse caso não usamos nenhuma função nova, apenas utilizando a função salvar que haviamos criado lá no inicio do passo a passo.
Acho que aqui é um bom momento para dar um introdução maior a respeito de Status Code.
STATUS CODE
O status-code é um inteiro de três dígitos que fornece o resultado da tentativa de entender e satisfazer uma requisição.
Os HTTP status code são extensíveis. Os clients HTTP não precisam entender o significado de todos os status code registrados, embora tal entendimento seja obviamente desejável. No entanto, um client DEVE compreender a classe de qualquer status-code, conforme indicado pelo primeiro dígito, e tratar um status-code não reconhecido como sendo equivalente ao status-code x00 dessa classe.
Por exemplo, se um status-code não reconhecido de 471 for recebido por um client, o client pode presumir que há algo errado com sua requisição e tratar a resposta como se tivesse recebido um status-code 400 (Bad Request).
A mensagem de resposta geralmente contém uma representação que explica o status. O primeiro dígito do status-code define a classe de resposta. Os dois últimos dígitos não têm nenhuma função de categorização. Existem cinco valores para o primeiro dígito:
- 1xx (Informational): A requisição foi recebida, continua o processo
- 2xx (Successful): A requisição foi recebida, compreendida e aceita com sucesso
- 3xx (Redirection): Outras ações precisam ser tomadas a fim de completar a requisição
- 4xx (Client Error): A requisição contém sintaxe incorreta ou não pode ser cumprida
- 5xx (Server Error): O servidor falhou ao atender a uma requisição aparentemente válida
Vou deixar aqui uma tabela de referencia com o link para a especificação de cada status code. Você não precisa decorar todos os códigos, basta ter próximo de você para quando precisar fazer uma consulta.
|Code | Reason-Phrase | Defined in...
| 100 | Continue | Section 6.2.1 |
| 101 | Switching Protocols | Section 6.2.2 |
| 200 | OK | Section 6.3.1 |
| 201 | Created | Section 6.3.2 |
| 202 | Accepted | Section 6.3.3 |
| 203 | Non-Authoritative Information | Section 6.3.4 |
| 204 | No Content | Section 6.3.5 |
| 205 | Reset Content | Section 6.3.6 |
| 206 | Partial Content | Section 4.1 of [RFC7233] |
| 300 | Multiple Choices | Section 6.4.1 |
| 301 | Moved Permanently | Section 6.4.2 |
| 302 | Found | Section 6.4.3 |
| 303 | See Other | Section 6.4.4 |
| 304 | Not Modified | Section 4.1 of [RFC7232] |
| 305 | Use Proxy | Section 6.4.5 |
| 307 | Temporary Redirect | Section 6.4.7 |
| 400 | Bad Request | Section 6.5.1 |
| 401 | Unauthorized | Section 3.1 of [RFC7235] |
| 402 | Payment Required | Section 6.5.2 |
| 403 | Forbidden | Section 6.5.3 |
| 404 | Not Found | Section 6.5.4 |
| 405 | Method Not Allowed | Section 6.5.5 |
| 406 | Not Acceptable | Section 6.5.6 |
| 407 | Proxy Authentication Required | Section 3.2 of [RFC7235] |
| 408 | Request Timeout | Section 6.5.7 |
| 409 | Conflict | Section 6.5.8 |
| 410 | Gone | Section 6.5.9 |
| 411 | Length Required | Section 6.5.10 |
| 412 | Precondition Failed | Section 4.2 of [RFC7232] |
| 413 | Payload Too Large | Section 6.5.11 |
| 414 | URI Too Long | Section 6.5.12 |
| 415 | Unsupported Media Type | Section 6.5.13 |
| 416 | Range Not Satisfiable | Section 4.4 of [RFC7233] |
| 417 | Expectation Failed | Section 6.5.14 |
| 426 | Upgrade Required | Section 6.5.15 |
| 500 | Internal Server Error | Section 6.6.1 |
| 501 | Not Implemented | Section 6.6.2 |
| 502 | Bad Gateway | Section 6.6.3 |
| 503 | Service Unavailable | Section 6.6.4 |
| 504 | Gateway Timeout | Section 6.6.5 |
| 505 | HTTP Version Not Supported | Section 6.6.6 |
MANIPULANDO MAIS ERROS
Nada novo sob o sol, se você estudou os links que deixei da primeira vez sobre error handling você não precisará de ajuda aqui.
CACHE DE TEMPLATE
Na área da computação, cache é um dispositivo de acesso rápido, interno a um sistema, que serve de intermediário entre um operador de um processo e o dispositivo de armazenamento ao qual esse operador acede. A principal vantagem na utilização de um cache consiste em evitar o acesso ao dispositivo de armazenamento - que pode ser demorado -, armazenando os dados em meios de acesso mais rápidos. wiki
Você deve talvez ter ouvido falar de caching a respeito de banco de dados, nesse caso estamos usando um intermediário mas para evitar que o código precise processar páginas com o mesmo estado, pois não faz sentido gastar processamento com algo que não foi modificado.
method template.ExecuteTemplate()
VALIDAÇÃO
Aqui fazemos a validação de um caminho relativo através do uso de expressões regulares.
Regex é uma forma de encontrar padrões em strings, lembra um pouquinho o comando grep do linux mas só lembra mesmo. A idédia é você buscar os padrões como por exemplo "quero somente palavras em maiusculas sem caracteres especiais".
Geralmente se usa bastante em formulários de cadastro para fazer com que o usuário envie dados formatados sem o risco da aplicação aceitar um dado que não se encaixa no com os dados solicitados. Como alguem enviar letras em um campo de telefone por exemplo.
Achei bem interessante esses slides e dão uma introdução clara de como regex funciona.
Regex - Bruno Croci [Slides]
method regexp.FindStringSubMatch()
LITERAL FUNCS E CLOJURES
Sobre Clojures eu achei um artigo bem interessante sobre o JavaScript Visualizer, ela mostra todo o funcionamento de Clojures simples ou complexos com a execução do código. E você vê em tempo real o que é feito a cada linha e como o programa se comporta.
Uma Clojure ela engloba uma segunda função que é recebida como parâmetro. Literal funcs é o mesmo que uma função anonima em outras linguagens.
Uma Função anônima ela não tem nome, no caso eu dei o nome da função dentro do clojure de função, mas esse não é um nome na verdade é o nome do parâmetro.
Funções Anônimas - StackOverFlow
NÃO PRECISA ACABAR
Chegamos ao final desse passo a passo e você aprendeu muito pelo caminho, desde funções e pacotes do Golang até métodos http e status code, apesar dessa ser uma bagagem ótima para iniciar com o desenvolvimento web apenas molhamos os pés nesse mar de roteadores que é a WWW. Ainda há muito pela frente, esse projeto não acaba aqui e você agora tem a sua disposição todos os repositórios que quiser ler. Se esse passo a passo tiver te ajudado compartilhe ele com os seus amigos que também precisam de ajuda no inicio da carreira em programação, ou que ainda não tem intimidade com o Github.
Caso tenha qualquer duvida fico disponível no Twitter para ajudar.
Parabéns por ter chegado até aqui.


