

Python além da ciência de dados: construindo APIs, insights e testes robustos
Quando se fala em Python, muitos associam imediatamente à ciência de dados. Mas será que o Python se limita apenas a essa área? A resposta é não. A linguagem alcança diversos campos, como backend, frontend, automação de testes e até mesmo inteligência artificial.
Este artigo aprofunda-se em três bibliotecas que representam bem essa versatilidade:
- Pandas, para manipulação e análise de dados.
- Flask, para criação de APIs e servidores leves.
- Pytest, para garantir qualidade com testes simples e poderosos.
Essas três ferramentas ajudam a quebrar a visão de que Python se restringe a dados. Tudo depende do contexto, e em inúmeras aplicações o Python demonstra ser altamente eficiente.
Python e sua versatilidade além da análise de dados
Python foi criado por Guido van Rossum no final da década de 1980 e lançado em 1991. Desde o início, não foi projetado apenas para ser uma potência em dados, mas sim como uma linguagem simples, com foco em legibilidade de código.
A proposta original era ser uma linguagem de script fácil de aprender, com sintaxe limpa, voltada à automação de tarefas.
O grande crescimento do uso de Python em ciência de dados ocorreu após o surgimento de bibliotecas poderosas como NumPy, Pandas e Matplotlib, no início dos anos 2000.
Essas ferramentas transformaram a análise em algo prático, possibilitando visualização e processamento de grandes volumes de dados de forma acessível.
Embora hoje Python seja um símbolo de Data Science e Machine Learning, essa é apenas uma das muitas capacidades da linguagem.
Manipulando e explorando dados com Pandas
O que é um DataFrame?
A analogia mais simples para entender um DataFrame é compará-lo a uma planilha do Excel ou a uma tabela de banco de dados.
Um DataFrame do Pandas é uma estrutura de dados bidimensional (linhas e colunas):
- Cada coluna pode armazenar um tipo de dado diferente (texto, números, datas etc.).
- Cada linha representa um registro.
- Tanto linhas quanto colunas possuem rótulos (índices), o que facilita a manipulação.
O objetivo principal da biblioteca Pandas é a manipulação e o tratamento de dados de forma simples e eficiente.
Leitura de dados
Uma das maiores vantagens do Pandas está na facilidade em carregar e tratar dados de diferentes fontes.
Exemplo:
import pandas as pd
# Lendo um arquivo CSV (Comma-Separated Values)
df_csv = pd.read_csv('caminho/para/seu/arquivo.csv')
print("Dados carregados de um CSV:"
print(df_csv.head()) # .head() mostra as 5 primeiras linhas
# Lendo de um banco de dados SQL
from sqlalchemy import create_engine
engine = create_engine('sqlite:///meu_banco.db')
query = "SELECT * FROM tabela_de_vendas"
df_sql = pd.read_sql(query, engine)
print("\nDados carregados de um banco SQL:")
print(df_sql.head())
Essa manipulação de dados tem importância fundamental. A possibilidade de trabalhar com qualquer tipo de dado ajudou a consolidar o Python como símbolo do Data Science.
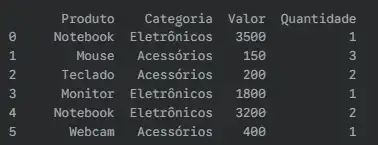
Exemplo prático:
#Podemos analisar no momento uma aplicação de tabela
import pandas as pd
# Criando um DataFrame de exemplo
dados = {
'Produto': ['Notebook', 'Mouse', 'Teclado', 'Monitor', 'Notebook', 'Webcam'],
'Categoria': ['Eletrônicos', 'Acessórios', 'Acessórios', 'Eletrônicos', 'Eletrônicos', 'Acessórios'],
'Valor': [3500, 150, 200, 1800, 3200, 400],
'Quantidade': [1, 3, 2, 1, 2, 1]
}
df_vendas = pd.DataFrame(dados)
A saida do DataFrame sera:
O que é uma API? A ponte entre aplicações
Uma API (Interface de Programação de Aplicações) funciona como um garçom em um restaurante. O usuário não vai à cozinha pegar a própria comida; solicita ao garçom, que traz o pedido.
A API atua como intermediária, permitindo que diferentes sistemas se comuniquem e troquem informações de forma organizada e segura.
Por que Flask? Por que utilizá-lo?
O Flask é um microframework que oferece desempenho poderoso mesmo sendo "micro". Permite construir aplicações web sem impor estruturas rígidas ou ferramentas desnecessárias.
Ele fornece o básico: rotas e tratamento de requisições. Se necessário, permite integração de funcionalidades adicionais. Assim, torna-se:
- Leve e rápido: inicia rapidamente e consome poucos recursos.
- Flexível: o desenvolvedor tem controle total sobre a estrutura do projeto e bibliotecas.
- Prótipagem: ideal para iniciar projetos, fácil de aprender e construir APIs.
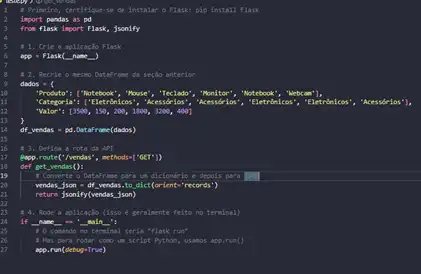
Exemplo prático: Servindo dados de vendas
A seguir, apresenta-se um código demonstrando a integração entre Flask e Pandas para criar uma API simples.
# Primeiro, certifique-se de instalar o Flask: pip install Flask
import pandas as pd
from flask import Flask, jsonify
# 1. Crie a aplicação Flask
app = Flask(__name__)
# 2. Recrie o mesmo DataFrame da seção anterior
dados = {
'Produto': ['Notebook', 'Mouse', 'Teclado', 'Monitor', 'Notebook', 'Webcam'],
'Categoria': ['Eletrônicos', 'Acessórios', 'Acessórios', 'Eletrônicos', 'Eletrônicos', 'Acessórios'],
'Valor': [3500, 150, 200, 1800, 3200, 400]
}
df_vendas = pd.DataFrame(dados)
# 3. Defina a rota da API
@app.route('/vendas', methods=['GET'])
def get_vendas():
# Converte o DataFrame para um dicionário e depois para JSON
vendas_json = df_vendas.to_dict(orient='records')
return jsonify(vendas_json)
# 4. Rode a aplicação (isso é geralmente feito no terminal)
if __name__ == '__main__':
# O comando no terminal seria "flask run"
# Mas para rodar como um script Python, usamos app.run()
app.run(debug=True)
O código cria um servidor web com Flask e carrega os dados de vendas em um DataFrame do Pandas.
Em seguida, define-se uma rota chamada /vendas. Ao acessar o endereço do servidor seguido de /vendas, a função get_vendas é executada.
A função converte o DataFrame para o formato JSON, padrão de comunicação web, e retorna os dados, permitindo que outros sistemas ou interfaces consumam essas informações.
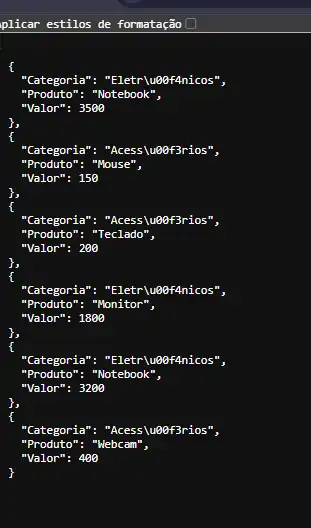
Com poucas linhas, foi criado um microserviço. Ele permite que dados de vendas sejam disponibilizados em tempo real, mesmo em bancos de dados grandes com muitas linhas e colunas.
Possíveis aplicações incluem:
- Uma equipe de front-end pode construir dashboards interativos que consomem a API e exibem os dados em gráficos.
- Aplicativos móveis podem acessar a API e mostrar informações de vendas na palma da mão.
- Sistemas internos podem usar a API para controle de estoque, identificando produtos mais vendidos.
Garantindo Qualidade com Pytest
Construir um software sem testes é comparável a construir uma ponte e só verificar sua segurança quando o primeiro carro passar por cima. Um código sem testes pode funcionar no desenvolvimento, mas falhar em produção.
Existem técnicas para testar aplicações antes da entrega, como BDD (Behavior Driven Development), TDD (Test Driven Development) e testes unitários.
Essa prática cria um código confiável, seguindo o conceito conhecido como Pirâmide de Testes.
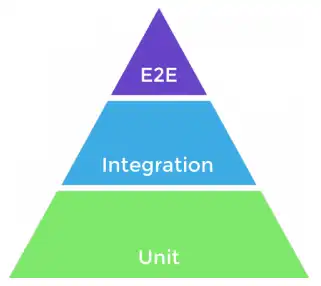
- Base forte em testes unitários
- Menos testes de integração
- Poucos testes end-to-end (E2E)
Essa pirâmide organiza os testes em três níveis principais.
Na base, os Testes Unitários são os mais numerosos; eles verificam a menor parte do código de forma isolada, como uma única função, garantindo que a lógica interna dela está correta.
No meio, os Testes de Integração verificam se diferentes partes do sistema conversam corretamente entre si por exemplo, se a nossa API Flask consegue se conectar e buscar dados de um banco de dados real.
No topo, os Testes End-to-End (E2E) são os menos numerosos, mas simulam a jornada completa de um usuário, garantindo que o fluxo completo da aplicação funciona como esperado, desde o clique em um botão na tela até a resposta da API.
A ausência desses testes pode acarretar falhas em produção, como:Bugs inesperados
- Perda de dados
- Queda de credibilidade
- Custos mais altos
Testes automatizados funcionam como uma rede de segurança para desenvolvedores, garantindo confiabilidade nas aplicações.
Testes usando Pytest
O Pytest é um framework que torna a escrita de testes em Python simples e legível. Ele segue uma convenção básica: criar um arquivo chamado test_*.py e, dentro dele, funções que comecem com test_*.
Um exemplo simples é a simulação de uma função de soma:
Arquivo calculadora.py
def somar(a, b):
"""Esta função retorna a soma de dois números."""
return a + b
Arquivo test_calculadora.py:
from calculadora import somar
def test_soma_positiva():
"""Testa a soma de dois números positivos."""
assert somar(2, 3) == 5
def test_soma_negativa():
"""Testa a soma de dois números negativos."""
assert somar(-1, -1) == -2
Note-se como é simples: utiliza-se apenas assert para verificar se o resultado de somar(2, 3) é 5. Não é necessário conteúdo complexo, pois o Pytest gerencia todo o processo.
Foram criadas e verificadas funções simples; entretanto, o verdadeiro poder de verificação ocorre quando ele é utilizado em uma aplicação.
Analisando a aplicação do projeto, é possível simular uma ação em que se verifica se a rota /vendas:
- Responde com sucesso (código de status 200)
- Retorna os dados no formato JSON
- Contém a quantidade correta de registros
Arquivo test_app.py:
import pytest
from app import app # Importamos nossa aplicação Flask do arquivo app.py
@pytest.fixture
def client():
"""Cria um cliente de teste para nossa aplicação Flask."""
with app.test_client() as client:
yield client
def test_get_vendas_sucesso(client):
"""Testa se a rota /vendas responde corretamente."""
# 1. Faz uma requisição GET para a rota /vendas
response = client.get('/vendas')
# 2. Verifica se a resposta foi bem-sucedida (status code 200)
assert response.status_code == 200
# 3. Verifica se o conteúdo da resposta é JSON
assert response.is_json
# 4. Pega os dados JSON da resposta
dados = response.get_json()
# 5. Verifica se os dados são uma lista e se contêm 6 itens
assert isinstance(dados, list)
assert len(dados) == 6
# 6. Verifica um dado específico para garantir a integridade
assert dados[0]['Produto'] == 'Notebook'
Analisando o código, a função decorada com @pytest.fixture, chamada client, é uma das funcionalidades mais poderosas do Pytest.
Ela prepara o ambiente para execução dos testes, garantindo que cada função tenha os recursos necessários de forma automatizada. Neste caso, client inicializa um “cliente de teste” da aplicação Flask, simulando o comportamento de um navegador que interage com a API.
O comando yield client fornece o cliente pronto para a função de teste e, ao final, realiza a limpeza do ambiente, evitando efeitos colaterais entre testes. Dessa forma, a função test_get_vendas_sucesso recebe client como argumento.
O Pytest injeta automaticamente essa preparação, tornando os testes limpos, reutilizáveis e consistentes.
A função utiliza o cliente para acessar a rota /vendas e aplica asserts para verificar status, formato JSON e integridade dos dados, garantindo robustez da aplicação.

A saída verde e a mensagem “3 passed” indicam que todos os testes, tanto da função somar quanto da API, foram executados com sucesso. Isso proporciona benefícios como:
- Confiança no código: a execução de testes após melhorias garante que nenhuma alteração quebrou funcionalidades existentes.
- Automação: com um simples comando, é possível realizar centenas de testes em segundos, economizando tempo e prevenindo erros humanos.
- Aprendizado facilitado: a utilização correta cria uma linha de desenvolvimento mais clara, facilitando a curva de aprendizado.
Desafios comuns e soluções práticas
Construir o fluxo inicial com Pandas, Flask e Pytest é rápido e poderoso. No entanto, à medida que um projeto evolui do protótipo para a produção, surgem novos desafios. Serão abordados três dos mais comuns, explorando soluções robustas que o ecossistema Python oferece.
Desempenho do Pandas com grandes volumes de dados
Pandas é excelente para manipulação de dados, mas pode apresentar limitações com datasets muito grandes (milhões de linhas). Algumas soluções incluem:
- Utilizar chunks (pd.read_csv(..., chunksize=10000)) para processar lotes de dados.
- Migrar para bibliotecas escaláveis, como Dask (processamento distribuído) ou Polars (colunar, mais rápido).
- Em cenários corporativos, considerar integração com bancos SQL para consultas otimizadas.
Estruturação de APIs em Flask conforme o projeto cresce
Projetos Flask pequenos funcionam bem em um único arquivo, mas à medida que o código cresce, a manutenção pode se tornar complicada. Algumas soluções incluem:
- Utilizar Blueprints, que permitem organizar rotas em módulos separados.
- Adotar padrões como Service Layer e Repository Pattern para separar a lógica de negócios da camada web.
- Para aplicações maiores, considerar migração para FastAPI, que oferece tipagem forte e documentação automática.
Manutenção de testes automatizados
Em equipes grandes ou projetos longos, manter os testes atualizados pode ser desafiador. Testes quebrados ou mal escritos acabam sendo ignorados. Algumas soluções incluem:
- Integrar o Pytest ao CI/CD (ex.: GitHub Actions, GitLab CI, Azure DevOps), garantindo que cada commit execute os testes automaticamente.
- Utilizar marcadores do Pytest (@pytest.mark.slow, @pytest.mark.integration) para separar tipos de testes.
- Adotar a filosofia “testar o que importa”, priorizando testes de regras de negócio críticas em vez de tentar cobrir tudo.
Aplicações práticas e próximos passos
Após percorrer o ciclo completo, da manipulação de dados com Pandas à criação de APIs robustas com Flask e testes com Pytest, surge a questão: onde aplicar esse conhecimento? A combinação dessas ferramentas abre diversas possibilidades, desde projetos simples até a base de aplicações complexas.
Alguns exemplos práticos incluem:
- Sistemas internos (Dashboards e relatórios):
Equipes podem usar Pandas para processar dados de campanhas, Flask para expor métricas (CPC, taxa de conversão) e dashboards simples para visualização. Em poucos dias, surge uma solução interna barata e personalizada.
- Protótipos rápidos para startups (MVP):
Com Pandas e Flask, é possível validar ideias de negócio de forma ágil. O Pytest garante estabilidade, permitindo entregar um produto funcional rapidamente a investidores ou usuários iniciais.
- Projetos acadêmicos e científicos:
Pesquisadores podem usar Pandas para análise de dados e Flask para criar APIs, permitindo que outros cientistas reproduzam experimentos e explorem novos parâmetros, em vez de publicar apenas resultados estáticos.
- Backend de aplicações reais:
O Flask é utilizado em larga escala por empresas como Netflix e Reddit. Em produção, deve ser executado com servidores como Gunicorn atrás de um Nginx, garantindo escalabilidade e segurança.
Possibilidades de expansão
- Evoluindo com FastAPI: APIs mais rápidas, tipadas e com documentação automática.
- Empacotando com Docker: garante que a aplicação funcione de forma consistente em qualquer máquina ou servidor.
- Automatizando com CI/CD: GitHub Actions executa os testes a cada push, proporcionando confiança contínua.
- Integrando Machine Learning: Pandas com Scikit-learn permite treinar modelos e expô-los em rotas Flask, como /predict, levando inteligência em tempo real para produção.
Conclusão
Limitar o Python ao universo dos dados é subestimar sua versatilidade e potência. A jornada apresentada neste artigo demonstra que Python permite criar fluxos de trabalho completos e profissionais.
Partindo do Pandas, foram extraídos insights valiosos de dados brutos, estruturando informações essenciais para o projeto.
Em seguida, Flask foi usado para construir um backend ágil, transformando os dados em um serviço funcional acessível via API.
Por fim, Pytest garantiu a qualidade e confiabilidade da aplicação, mostrando que velocidade e robustez podem coexistir.
O ecossistema Python, com bibliotecas maduras e sintaxe simples, permite que equipes pequenas construam, testem e entreguem soluções completas em tempo recorde.
Seja para criar dashboards internos, validar ideias de negócio ou colocar modelos em produção, as ferramentas certas estão disponíveis. O próximo passo é experimentar em projetos pequenos e explorar todo o potencial do Python.
Referências
Para saber mais sobre as bibliotecas mencionadas e aprofundar seus conhecimentos, seguem os links para as documentações oficiais:
- Pandas: https://pandas.pydata.org/docs/
- Flask: https://flask.palletsprojects.com/
- Pytest: https://docs.pytest.org/
- GitHub projeto: https://github.com/CainanJose/Artigo_python.git




