

Por que a acurácia (accuracy) não é a melhor métrica para avaliar o desempenho de classificadores?
- #Python
- #Jupyter
- #Machine Learning
Nos problemas de classificação, queremos predizer se determinado valor pertence ou não a uma categoria ou, qual a probabilidade de pertencer àquela categoria. Para alguns tipos, a acurácia pode até ser uma boa métrica para avaliar o desempenho do modelo, mas no geral, quando temos um conjunto de dados desbalanceados, essa métrica pode simplesmente não nos dizer muito, especialmente quando estamos tratando de dados desbalanceados. Entende-se por conjunto de dados desbalanceados os tipos de dados onde a proporção de uma categoria da variável que se deseja prever é muito menor que a outra. Por exemplo, imagine que temos um problema onde precisamos prever se a cor de uma bola é verde ou não, e nosso dataset dispõe de dados sobre 1000 bolas, das quais apenas 50 são Verdes e 950 são Não-verdes.
Se usarmos a acurácia como métrica de um modelo para predizer a classificação dessa categoria, o desempenho da métrica será muito semelhante à probabilidade de que, no exemplo acima, ao retirar 100 bolas de uma caixa, 5 sejam Verdes (50 em 1000, ou 5%).
O que fazer?
Para problemas com classes desbalanceadas, precisamos separar os diferentes tipos de erros que ocorrem no ajuste, e ver de que forma nosso modelo prediz cada classe. Para entender melhor, vamos prosseguir com o conceito de Matriz de Confusão.
Matrix de Confusão (Confusion Matrix)
A Matriz de Confusão é uma tabela que permite analisar melhor o desempenho do modelo, analisando de que forma cada predição, certa ou errada, foi feita. Ela tem a seguinte forma:
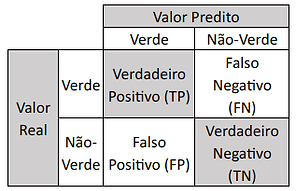
Matriz de Confusão (ou Matriz de Erro)
Prossigamos no exemplo do modelo que prediz se a bola é Verde ou Não-Verde. Na Matriz de Confusão vemos que as linhas apresentam os valores reais, ou seja, a verdadeira categoria da bola, e as colunas apresentam as cores preditas pelo modelo. Assim, em cada célula da tabela, temos:
- TP (Verdadeiro Positivo ou True Positive): o modelo predisse Verde, e de fato, o dado era Verde.
- FP (Falso Positivo ou False Positive): o modelo predisse Verde, mas a cor era Não-Verde.
- FN (Falso Negativo ou False Negative): o modelo predisse Não-Verde, mas na verdade, era Verde.
- TN (Verdadeiro Negativo ou True Negative: o modelo predisse Não-Verde, e de fato era Não-Verde.
Se somarmos TP e FN, obteremos o total de bolas do tipo Verde existentes (valores reais), e caso somemos os valores de TP e FP obteremos o total de bolas do tipo Verde predito pelo modelo. Assim, como se somarmos FP e TN, teremos o total de bolas Não-Verde existentes (valores e reais) e se somarmos FN e TN teremos o total de bolas Não-Verdes preditos pelo modelo.
A partir da Matriz de Confusão, podemos obter outras métricas que fazem muito mais sentido para classificadores. Vejamos algumas a seguir.
Precisão (Precision)
A Precisão é a acurácia das previsões positivas, e é definida por:
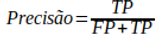
Se olharmos para a equação acima, vemos que a Precisão é a razão entre os Verdadeiros Positivos (positivos reais) e o número de predições Positivo (FP+TP). Basicamente ela responde à seguinte pergunta: “Quando o modelo predisse que seria Verde, quantas vezes ele acertou?” ou ainda, “Quão preciso o modelo foi ao predizer Verde?”.
Revocação (Recall)
A Revocação é a taxa de verdadeiros positivos, dada por:
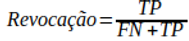
De acordo com a equação acima, vemos que seu significado reside na taxa de instâncias positivas que são corretamente detectadas pelo classificador, ou seja, ele responde à pergunta: “Da quantidade real de Verde existentes (FN+TP), quantas o modelo acertou (TP)?”. O que há de mais importante na Revocação, é pensar “será que o modelo deixou escapar alguma bola Verde?” e responder quão importante isso é para o nosso problema de negócio.
F1-score
Uma das métricas que combinam a Precisão e a Revocação é a F1-score, calculado pela equação abaixo:
Trata-se da média harmônica da Precisão e Revocação. A média harmônica é geralmente utilizada quando envolve variáveis inversamente proporcionais. Ela dá mais peso aos valores mais baixos (aos “scores ruins”), favorecendo classificadores com precisão e revocação similares. Para que F1-score possua um alto valor, é necessário, de fato, que ambas as métricas em questão também possuam altos valores.
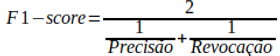
Trade-off Precisão e Revocação
Em grande parte dos modelos preditivos, é possível alterar o parâmetro Threshould (limiar) para que tenhamos uma maior Precisão ou Revocação, mas nunca aumentar as duas juntas, pois elas são inversamente proporcionais. Para entender como funciona o Threshould, voltemos ao exemplo inicial das bolas Verdes e Não-verdes.
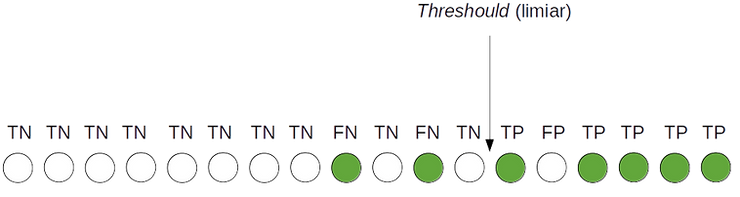
Consideremos a seta indicado na figura acima como o Threshould. Do lado direito, temos as previsões feitas pelo modelo classificando as bolas como Verdes, e do lado esquerdo como Não-Verdes. Isso significa que as bolas Verdes do lado direito são TP, e do lado esquerdo são as FN. Já as bolas Não-Verdes que estiverem do lado direito, (classificadas como Verdes), são FP e as bolas Não-verdes que estiverem do lado esquerdo, são as TN. Vamos calcular a Precisão e a Revocação para o Threshould acima:
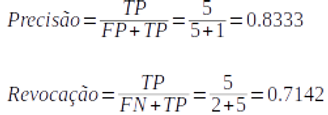
Agora vamos mover o Threshould mais para a esquerda e calcular novamente:
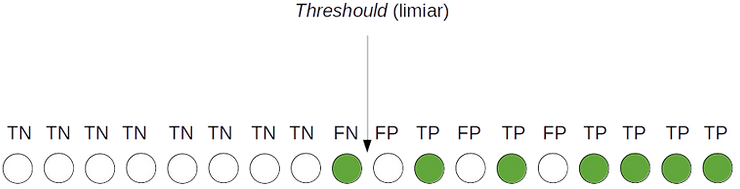
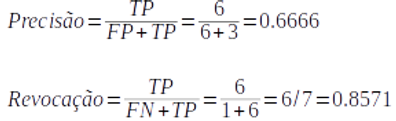
Vemos que, além de serem inversamente proporcionais, uma diminuição no Threshould diminuiu a Precisão (de 0.8333 para 0.6666, no exemplo), mas aumentou a Revocação (de 0.7142 para 0.8571). Portanto, observamos que é possível modificar a relação Precisão-Revocação a partir do ajuste do Limiar.
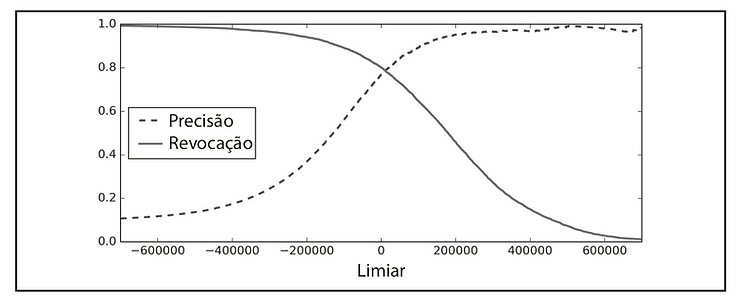
Precisão — Revocação vs. Limiar (Threshould)
O gráfico acima ilustra uma relação entre Precisão e Revocação em função do limiar ( Threshould). Quando a Precisão aumenta, a Revocação diminui, e vice-versa. Um aumento no limiar pode causar um aumento na Revocação e diminuição na Precisão.
Uma vez que podemos modificar o Threshould para aumentar a Precisão ou o Revocação, podemos melhorar nosso modelo de acordo com a necessidade, avaliando as características do problema. Por exemplo, vamos supor que queremos construir um modelo para prever se um vídeo é ou não adequado para crianças. O interesse, neste caso, é aumentar a precisão, pois do total de vídeos que o modelo classificar como infantil (TP+FP), queremos que ele acerte muito (alto TP) e diminuia a possibilidade de que vídeos Não-Infantis sejam assistidos pelas crianças. Pouco importa se ele possui baixo Recall e classifica vídeos infantis como sendo vídeos para adultos e não recomenda esse vídeo para a criança (o prejuizo ao usuário é pequeno) . O modelo pode até não detectar todos os vídeos infantis, mas ele não deixará que vídeos adultos sejam classificados como infantis.
Agora imagine que queremos treinar um modelo para classificar se um paciente tem câncer ou não. Nesse caso, queremos que de todas as pessoas que realmente tem câncer, (FN+TP), tenhamos o maior TP, ainda que tenhamos uma baixa Precisão. Veja que, nesse caso, não interessa tanto se o modelo possui alta Precisão, pois o que queremos é que as pessoas que de fato possuem câncer sejam diagnosticadas corretamente (queremos uma alta Revocação) ainda que pessoas que não possuam câncer, sejam diagnosticadas como possuindo, pois nesse caso, o problema seria menor (na verdade, isso poderia levar a outros problemas de cunho ético, mas é melhor não ter câncer e ser diagnosticado como tendo, do que ter e ser diagnosticado como não tendo a doença).
Para você refletir: se tivermos um problema de classificação de e-mail como spam, o que é mais importante, alta precisão ou alta revocação?
Conclusão
Neste artigo, procurei mostrar que, para dados desbalanceados, a métrica Accuracy não é a mais indicada, e que é necessário analisar mais detalhadamente de que forma o modelo faz as previsões, para obter a Matriz de Confusão, e a partir dela, outras métricas como Precisão, Revocação e Recall. Vimos ainda que há de se considerar o trade-off entre Precisão e Revocação, de acordo com o tipo de problema em questão, e que é possível obter modelos com valores ajustáveis para elas, alterando o parâmetro limiar (Threshould).
Referências
GÉRON, Aurélien. Mãos à Obra Aprendizado de Máquina com Scikit-Learn & TensorFlow: Conceitos, Ferramentas e Técnicas Para a Construção de Sistemas Inteligentes. Rio de Janeiro: ALTA BOOKS, 2019. 576 p.
Machine Learning — Foundational courses. Classification: Thresholding . [ S. l.], 6 set. 2022. Disponível em: https://developers.google.com/machine-learning/crash-course/classification/accuracy. Acesso em: 6 set. 2022.




