

Modelagem e Design de Bancos de Dados Relacionais: Construindo uma Base Sólida
- #SQL
- #Banco de dados relacional
A modelagem de dados é uma ferramenta essencial que ajuda os projetistas a comunicar de forma eficaz os conceitos presentes em suas mentes. Ela é utilizada para diversas tarefas, como descrever, analisar, especificar e comunicar ideias relacionadas a um projeto. Um modelo deve ser detalhado o suficiente para permitir que os desenvolvedores construam um banco de dados de acordo com as exigências do projeto.
O Conceito de Modelagem de Dados
Modelagem de dados é um processo no qual se cria um modelo de dados para um sistema de informação, aplicando técnicas específicas de modelagem. Essas técnicas são empregadas para definir e analisar os requisitos de dados necessários para dar suporte aos processos de negócio por meio de sistemas informatizados em organizações. Um modelo de dados oferece uma estrutura que define e organiza os dados utilizados em um Sistema de Informação (SI), com definições e formatos específicos.
Explorando Modelos de Dados
Dentro da modelagem de dados, existem diversos tipos de modelos, incluindo:
- Modelo Hierárquico
- Modelo de Rede
- Modelo Relacional (que será nosso foco)
- Modelo Orientado a Objeto
- Modelos Não-Relacionais
O modelo relacional foi concebido por E.F. Codd da IBM, que propôs uma abordagem revolucionária em um artigo intitulado “A relational Model of Data for Large Shared Data Banks”. Antes disso, modelos como o hierárquico e o em rede eram predominantes.
No modelo relacional, os dados são organizados em tabelas bidimensionais chamadas de “relações”. Uma relação é uma forma de estruturar os dados em linhas e colunas, baseando-se em princípios lógicos e teoria de conjuntos.
Componentes do Modelo Relacional
O modelo relacional é composto pelos seguintes elementos fundamentais:
- Coleções de relações ou objetos que armazenam os dados.
- Um conjunto de operadores que atuam nas relações, gerando novas relações.
- Garantia de integridade de dados para assegurar precisão e consistência.
Entendendo o Banco de Dados Relacional
Um banco de dados relacional é uma coleção de relações, que são representadas como tabelas bidimensionais onde os dados são armazenados. Por exemplo, ao lidar com informações sobre clientes, pode-se criar tabelas para armazenar detalhes pessoais, histórico de compras, crédito e outros dados relacionados.

Tabela cliente registrando informações importantes
Os Componentes de um Banco de Dados Relacional
Dentro de um Sistema Gerenciador de Banco de Dados Relacional (SGBDR), os seguintes componentes são essenciais:
- Tabela: A unidade básica de armazenamento, representando informações do mundo real, como clientes, pedidos ou produtos.
- Tupla: Também conhecida como linha ou registro, representa uma ocorrência específica de uma entidade, como um cliente individual.
- Coluna: Contém um tipo específico de dado ou valor, podendo ser nula em algumas circunstâncias.
- Relacionamento: Associação entre entidades, estabelecida por meio de chaves primárias e estrangeiras.
- Outros elementos: Índices, Stored Procedures (SP), Triggers, entre outros.
- Chave Primária (PK): Coluna que identifica de forma única um registro na tabela, como o CPF de um cliente.
- Chave Estrangeira (FK): Coluna que estabelece conexões entre tabelas, referindo-se a chaves primárias ou únicas em outras tabelas.
A Importância da Análise de Requisitos
Na fase de análise de requisitos, ocorrem reuniões para coletar informações essenciais para o desenvolvimento do banco de dados. Os processos de negócio são definidos e as entidades, atributos e relacionamentos são cuidadosamente documentados. Essa análise é vital para o sucesso geral do projeto do banco de dados.
O Papel do Modelo Entidade-Relacionamento (MER)
O Modelo Entidade-Relacionamento (MER) é construído durante a análise de requisitos e ilustra as entidades presentes em um negócio, bem como os relacionamentos entre elas. Ele ajuda a discernir quais dados serão armazenados, como clientes, produtos e vendas, e como esses elementos estão interconectados.
O MER também auxilia a compreender as atividades executadas pelo negócio, como compras e vendas, e como essas atividades se relacionam entre si.
Componentes e Convenções do MER
Os principais componentes do MER são:
- Entidade: Um elemento significativo sobre o qual informações devem ser registradas.
- Atributo: Uma característica que descreve uma entidade.
- Relacionamento: Uma associação nomeada entre entidades.
As convenções incluem:
- Nomes de entidades em maiúsculas e singulares.
- Nomes de atributos em minúsculas e singulares, indicando obrigatoriedade ou unicidade quando necessário.
- Nomes de relacionamentos em forma de verbo, indicando opcionalidade e cardinalidade (quantidade de conexões possíveis entre entidades).
A Importância do Identificador Único (UID)
Um identificador único é um conjunto de atributos ou relacionamentos que distinguem exclusivamente as ocorrências de uma entidade. É qualquer combinação de atributos ou relacionamentos que são usados para distinguir ocorrências de uma entidade. Cada ocorrência da entidade deve ser identificável de forma exclusiva.
Níveis
Classificamos o processo de modelagem de dados em três níveis:
- Modelo Conceitual (alto nível) — MCD
- Modelo lógico — MLD
- Modelo Físico (baixo nível) — MFD
Compreendendo o Modelo Conceitual na Modelagem de Dados
A fase inicial da modelagem é o Modelo Conceitual. Nesse estágio, representamos o mundo real de forma simplificada, destacando os dados e suas relações. Essa visão nos ajuda a decidir quais informações devem ser guardadas no banco de dados, sem depender do Sistema Gerenciador de Banco de Dados (SGBD).
Por exemplo, pensemos em um cadastro de produtos para uma loja. Aqui estão alguns detalhes necessários:
- Nome do produto
- Categoria do produto (como limpeza, higiene, etc.)
- Código do fornecedor
- Tipo de embalagem
- Tamanho do produto
- Quantidade disponível
Nesse nível, não estamos focando nos detalhes de como tudo será implementado. No entanto, já conseguimos descrever os tipos de informações necessárias, como elas se relacionam e as regras para garantir consistência.
Modelo Lógico: Traduzindo Conceitos para um Nível Entendível
O Modelo Lógico é como um tradutor entre as ideias dos usuários e a realidade do banco de dados. Ele é próximo o suficiente do modelo físico, que é como o banco de dados é realmente construído, mas é apresentado de uma maneira que faz sentido para todos. Nesse estágio, não estamos presos a um Sistema Gerenciador de Banco de Dados (SGBD) específico.
Aqui, definimos exatamente como os dados serão organizados e utilizados. Por exemplo, se pensarmos em um sistema de cadastro de clientes, decidimos que informações como “Nome do Cliente”, “ID do Cliente” e “Endereço” são importantes. Tudo é descrito de forma lógica e compreensível.
Modelo Físico: Criando uma Estrutura Real a Partir da Lógica
A partir do Modelo Lógico, desenvolvemos o Modelo Físico. Isso envolve detalhar como o banco de dados será construído na prática. Isso inclui coisas como criar tabelas, definir campos, tipos de dados e regras para garantir a integridade dos dados.
Imagine que temos um Modelo Lógico para um cadastro de clientes. No Modelo Físico, isso se transforma em tabelas reais com campos específicos. Por exemplo:

Agora, essa estrutura detalhada pode ser implementada em um SGBD para criar o banco de dados de fato. É como transformar um plano em algo tangível.
Os Modelos Lógico e Físico são etapas importantes na criação de um banco de dados. O Modelo Lógico traduz conceitos em uma forma fácil de entender, enquanto o Modelo Físico detalha como esses conceitos serão transformados em uma estrutura concreta, pronta para ser usada por um SGBD específico. Juntos, esses modelos permitem que ideias se tornem realidade de maneira organizada e eficaz.
Compreendendo a Arquitetura de Três Níveis na Construção de Bancos de Dados
Imagine que a construção de um banco de dados é como criar um quebra-cabeça. Começamos com a imagem geral e, aos poucos, encaixamos as peças até formar a imagem completa.
1. Mundo Observado -> Modelo Conceitual
No começo, olhamos para o mundo ao nosso redor, onde encontramos o que queremos representar no banco de dados. Isso é como a primeira peça do quebra-cabeça. A partir daí, criamos um “modelo conceitual”. Imagine como desenhar um mapa do que você quer no banco de dados, mas de forma simplificada.
2. Modelo Conceitual -> Modelo Lógico
Agora, olhamos para nosso desenho simplificado e adicionamos mais detalhes. Isso é o “modelo lógico”. Imagine preencher mais informações no mapa, mas ainda de uma forma que todos possam entender. Nesse ponto, já sabemos exatamente quais informações são importantes.
3. Modelo Lógico -> Modelo Físico
Agora que temos o mapa detalhado, vamos transformá-lo em algo real. Isso é o “modelo físico”. É como montar o quebra-cabeça peça por peça, encaixando tudo nos lugares certos. Aqui é onde os detalhes ficam muito claros, quase como olhar bem de perto para cada peça do quebra-cabeça.
Esquema de Banco de Dados: Como Organizar Tudo
Pense no “esquema” como as instruções para montar o quebra-cabeça. Ele é feito durante o planejamento e guardado em um “dicionário de dados”. Este esquema raramente muda enquanto construímos o banco de dados. É como um plano que mostra como todas as peças se encaixam: as tabelas, as partes importantes, como elas se relacionam e até mesmo as diferentes visões e funções.
Etapas para Criar um Banco de Dados
Aqui estão as etapas principais para construir um banco de dados, como montar o quebra-cabeça:
- Especificar e Analisar Requisitos - Os requisitos são documentados (quais informações vou utilizar e quais posso descartar para o BD? Uma fase muito importante, precisa ser documentado
- Projeto Conceitual - Baseado nos requisitos
- Projeto Lógico - Expresso em um modelo de dados, como o relacional
- Projeto Físico - Especificações para armazenar e acessar o banco de dados, implementação do BD, inserção de dados reais e manutenção
Desvendando o Modelo Entidade-Relacionamento e seus Diagramas
Imagine que estamos criando um mapa para entender como diferentes coisas se relacionam. Isso é o que um Modelo Entidade-Relacionamento, também conhecido como MER, faz. Ele nos ajuda a visualizar de forma organizada o que faz parte de um sistema e como tudo se encaixa.
O que é um Modelo Entidade-Relacionamento (MER)?
Pense nisso como uma lista que descreve os objetos de um sistema que queremos construir. Esses objetos podem ser coisas como “clientes”, “produtos” ou “pedidos”. O MER nos ajuda a entender a estrutura dessas coisas e como elas se relacionam. Você pode ver isso como um esboço abstrato do que nosso banco de dados vai ser.
O MER tem três partes principais:
- Entidades: São os objetos, como “clientes” ou “produtos”.
- Atributos: São as características desses objetos, como “nome” ou “número”.
- Relacionamentos: São as conexões entre esses objetos, mostrando como eles dependem uns dos outros.
Como Funciona o MER?
Imagine que estamos montando um quebra-cabeça. Cada peça do quebra-cabeça representa uma parte de um processo de negócio. Essas peças (ou entidades) são conectadas por linhas (ou relacionamentos) que mostram como elas se influenciam. Além disso, cada peça tem detalhes (ou atributos) que a caracterizam.
Modelo e Diagrama: O que são?
O Modelo Entidade-Relacionamento é como a planta de uma casa, listando todas as peças e suas descrições. Enquanto isso, o Diagrama Entidade-Relacionamento (DER) é como uma foto dessa planta. Ele nos mostra visualmente como as peças estão conectadas.
Componentes dos Diagramas:
- Retângulos: Representam as peças principais, ou seja, as entidades.
- Elipses: Representam as características dessas peças, chamadas de atributos.
- Losangos: Mostram as conexões entre as peças, que são os relacionamentos.
- Linhas: Liga os atributos às entidades e as entidades aos relacionamentos.

Imagine que estamos desenhando um mapa simples, onde usamos formas diferentes para mostrar diferentes coisas. Da mesma forma, esses diagramas nos ajudam a ver como tudo se encaixa de um jeito visual.
O Modelo Entidade-Relacionamento e seus diagramas são como mapas que nos ajudam a entender o que faz parte de um sistema e como todas as partes se ligam. Eles nos permitem visualizar facilmente os objetos, suas características e como eles estão conectados. É como olhar para um quebra-cabeça e entender como cada peça se encaixa para formar a imagem completa.
Entendendo o Conceito de Entidade e suas Características
Vamos explorar o que é uma “entidade” e como ela se relaciona com os bancos de dados. Imagine que estamos catalogando coisas importantes para uma organização, como peças de um quebra-cabeça. Cada peça desse quebra-cabeça é uma entidade, algo que importa para a organização e precisa ser registrado.
O que é uma Entidade?
Uma entidade é algo significativo para uma pessoa ou empresa, e que desejamos manter registro em um banco de dados. Pense nisso como um tópico ou ideia principal. Cada objeto específico de uma entidade é chamado de “instância de entidade”. Pode ser algo real, como “funcionários” ou “produtos”, ou algo mais abstrato, como “vendas” ou “estoque”.
Nomeando Entidades de Forma Inteligente
Para facilitar, usamos nomes que descrevem claramente o que a entidade representa. Por exemplo, se estamos construindo um sistema para uma loja, podemos ter entidades como “PRODUTO”, “CLIENTE”, “VENDA” e “CATÁLOGO”. É uma boa prática usar o nome no singular, mesmo que a entidade represente várias coisas.
Regras de Nomenclatura para Entidades (Dicas Úteis)
Quando nomeamos entidades, existem algumas regras a seguir:
- O nome deve começar com uma letra.
- Use palavras no singular.
- Evite espaços e certos caracteres especiais.
- Alguns caracteres como “$”, “#” e “_” podem ser permitidos em alguns bancos de dados.
Cada Peça do Quebra-Cabeça: Instância de Entidade
Imagine que estamos criando um manual de instruções para construir um objeto. A entidade é como o plano geral, enquanto a “instância de entidade” é um exemplo específico disso. Por exemplo, a entidade “PRODUTO” é o plano geral de como os produtos serão tratados no banco de dados. Uma “instância de entidade” de “PRODUTO” seria um produto real, como um livro ou um brinquedo.
Entidades são os blocos de construção dos bancos de dados. Elas representam ideias ou coisas importantes e podem ser algo real ou mais conceitual. As instâncias de entidade são como exemplos específicos dessas ideias. Escolher nomes adequados e seguir as regras ajuda a manter tudo organizado e fácil de entender. É como montar um quebra-cabeça, onde cada peça tem seu lugar específico.
- - - - - - - - - - - - - - - - - +
| Carro |
+ - - - - - - - - - - - - - - - - +
| CarroID |
| Fabricante |
| Modelo |
| Cor |
| Placa |
+ - - - - - - - - - - - - - - - - +
Neste diagrama simplificado, “Carro” é a entidade principal com os atributos “CarroID” (chave primária), “Fabricante”, “Modelo”, “Cor” e “Placa”. Cada linha na tabela representa um carro único com suas características correspondentes. A chave primária “CarroID” é usada para identificar cada carro de forma única.
- - - - - - - - - - - - - - - - - +
| Carro |
+ - - - - - - - - - - - - - - - - +
| 1 |
| Ford |
| Fiesta |
| Azul |
| AXJ-4010 |
+ - - - - - - - - - - - - - - - - +
- - - - - - - - - - - - - - - - - +
| Carro |
+ - - - - - - - - - - - - - - - - +
| 2 |
| Citroen |
| C3 |
| Vermelho |
| BUZ-3667 |
+ - - - - - - - - - - - - - - - - +
Um “Carro” é como um tipo principal de "coisa". É um termo amplo que cobre muitos veículos diferentes.
Quando falamos de marcas específicas, como “Ford” e “Citroen”, estamos falando de instâncias individuais desse tipo principal de coisa, ou seja, exemplos específicos de carros. Ambos são considerados carros, mas têm suas próprias características únicas, como cores diferentes, placas diferentes e modelos diferentes.
“Modelo” e “cor” são como detalhes especiais de um carro. Eles não podem existir sozinhos, precisam estar relacionados a um carro específico. Por exemplo, não dizemos apenas “modelo” ou “cor”, mas sim “modelo do carro” ou “cor do carro”.
Em resumo, um “Carro” é o conceito geral, enquanto “Ford” e “Citroen” são exemplos específicos desse conceito. E características como “modelo” e “cor” são detalhes importantes que pertencem a cada carro individualmente.
Atributos e Tipos de Atributos
Atributos são características importantes de uma coisa. Imagine que estamos falando sobre carros. Alguns atributos de um carro são como suas informações, como o fabricante, modelo, cor e placa. Cada atributo tem um tipo, que é o que ele representa, como um número, texto ou data.
Atributo Simples / Atômico
Um atributo simples é como um detalhe que não pode ser dividido mais. Por exemplo, o nome de uma empresa, um CPF ou um CNPJ. Não dá para quebrar esses atributos em partes menores.
---------------
| Empresa |
---------------
Nome da Empresa
Atributo Composto
Um atributo composto é feito de pedaços menores. Pode ser algo como o endereço de uma empresa, que tem partes como rua, número e CEP. No entanto, é importante lembrar que não é a melhor ideia guardar todos esses detalhes juntos. É como uma quebra-cabeça que pode ser separado para facilitar a organização e busca.
--------------
| Empresa |
--------------
Rua Número
| |
Endereço CEP
| |
Bairro Complemento
Atributo Multivalorado
Alguns atributos podem ter mais de um valor para a mesma coisa. Por exemplo, um telefone de uma empresa pode ter vários números, ou uma pessoa pode ter mais de um telefone.
--------------
| Empresa |
--------------
*Telefone
- O asterisco é a representação gráfica do atributo multivalorado
Atributo Determinante
Um atributo determinante é como um selo que faz algo único. Ele ajuda a distinguir uma coisa das outras. Por exemplo, o CNPJ de uma empresa ou um código de produto. Não pode haver duas coisas com o mesmo CNPJ ou código de produto.
Um atributo determinante é como um selo que faz algo único. Ele ajuda a distinguir uma coisa das outras. Por exemplo, o CNPJ de uma empresa ou um código de produto. Não pode haver duas coisas com o mesmo CNPJ ou código de produto.
--------------
| Empresa |
--------------
CNPJ
Atributos Identificadores (“Chaves”)
Uma chave é como uma etiqueta especial que ajuda a encontrar uma coisa única. Por exemplo, imagine que estamos falando sobre pessoas. Um CPF, um código de produto, uma matrícula ou um ID de setor podem ser chaves. Elas nos ajudam a saber exatamente qual pessoa ou coisa estamos falando.
Existem dois tipos de chaves:
- Únicas: Isso significa que o valor da chave é como um nome especial que só pertence a uma única pessoa ou coisa na nossa lista.
- Não-única: Essa chave não é tão única, mas é usada para organizar as pessoas ou coisas em grupos.
Algumas chaves podem ser como uma mistura de mais de uma coisa. Pode ser como juntar duas ou mais palavras para criar uma chave única.
Exemplos de representação de entidades e atributos
-----------------------
| Produto |
-----------------------
| PK | ___Cod_Produto |
-----------------------
| | Nome_Produto |
-----------------------
| | Preço |
-----------------------
| | Qtde_Estoque |
- Entidade com atributos e uma chave primária (PK)
Entidade vs. Relação
Imagine “Entidade” como um nome para algo real, como um Cliente ou um Produto. Por outro lado, “Relação” é como uma lista de informações sobre essas coisas.
Relação
Uma Relação é como uma tabela que guarda informações sobre Entidades. Cada linha na tabela é como uma coisa real (uma instância de Entidade), e cada coluna é como uma característica importante dessa coisa (um atributo).
Características de uma Relação:
- Cada célula na tabela guarda um valor único.
- Todas as informações em uma coluna são do mesmo tipo.
- Cada coluna tem um nome único.
- Não existem duas linhas iguais.
- Relações frequentemente se transformam em tabelas em bancos de dados.
Exemplo de uma Relação:
Vamos usar a relação “PRODUTO” como exemplo:

Toda Relação é uma tabela, mas nem toda tabela é uma Relação
Relacionamentos
Pense nos relacionamentos como as conexões especiais entre diferentes coisas (entidades). É como dizer que coisas diferentes estão ligadas de alguma forma.
Por que precisamos de Relacionamentos?
Quando guardamos informações de coisas diferentes em tabelas separadas, às vezes queremos saber como essas coisas se conectam. Por exemplo, podemos querer descobrir quais produtos um cliente comprou. Para isso, precisamos juntar informações das tabelas de clientes, pedidos e produtos.
Como representamos Relacionamentos
Para mostrar essas conexões no nosso diagrama (DER), usamos um símbolo parecido com um losango. Ele liga as entidades para mostrar que elas têm alguma ligação especial.

O usuário possui um currículo — é o relacionamento
Grau de relacionamento
O grau de um relacionamento define o número de entidades que participam do relacionamento.
Um relacionamento pode ser:
- Unário
- Binário
- Ternário
Os relacionamentos mais comuns são os de grau binários
Relacionamento unário (Recursivo)
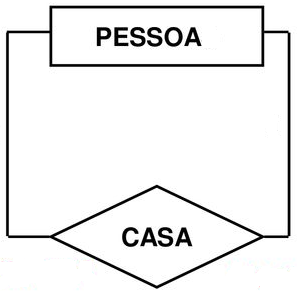
O relacionamento dessa entidade é intrincado, pois está intrinsecamente ligado a si mesma. Isso significa que o relacionamento não segue uma direção única, mas sim um ciclo que vai e volta. Embora seja menos comum, é importante destacar que ocasionalmente esse tipo de conexão pode ocorrer. Esse tipo de dinâmica complexa pode ser desafiador de compreender e gerenciar, uma vez que envolve uma constante interação consigo mesma.
Relacionamento Binário
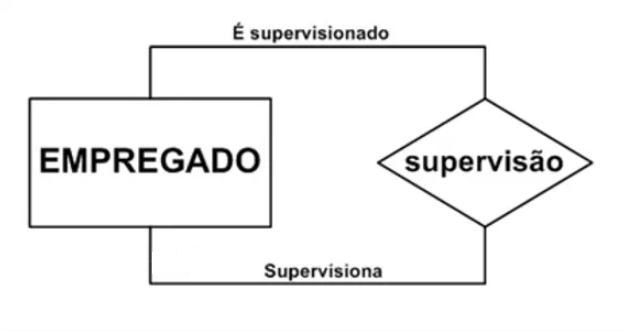
O relacionamento mais comum envolve a interação entre os empregados e a supervisão dentro de uma organização. Basicamente, esse arranjo implica que cada empregado está sob a supervisão de um membro da equipe de supervisão. No entanto, é importante observar que essa dinâmica pode variar, uma vez que a supervisão, por sua vez, pode estar encarregada de supervisionar não apenas um, mas vários empregados.
Relacionamento Ternário
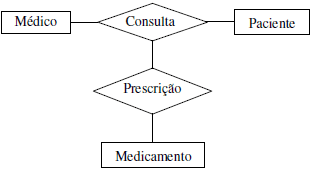
Esse cenário envolve três entidades fundamentais: o médico, o medicamento e o paciente. A relação intrincada entre essas entidades pode ser descrita da seguinte maneira:
O médico desempenha um papel essencial, pois PRESCREVE o medicamento necessário ao paciente. Isso implica que o paciente depende do médico para que ele PRESCREVA o medicamento apropriado, atuando como o elo crítico na cadeia. Enquanto isso, o medicamento, por sua vez, é PRESCRITO especificamente para atender às necessidades do paciente. Portanto, o verbo “PRESCREVER” representa a conexão vital entre essas entidades, garantindo que o tratamento médico seja adequadamente administrado e supervisionado para o bem-estar do paciente.
Relacionamento entre tabelas
Os relacionamentos entre tabelas são um elemento crucial no design de bancos de dados. Isso envolve estabelecer conexões significativas entre diferentes conjuntos de dados para uma gestão eficaz das informações.
Um exemplo simples para ilustrar esse conceito é a relação entre uma tabela de “PRODUTO” e uma tabela de “LOJA”. Nesse cenário, cada produto é vendido em uma loja específica, o que demonstra a interligação entre essas duas tabelas. O grau de relacionamento entre elas pode ser classificado de acordo com o número de entidades envolvidas. Por exemplo, um relacionamento unário envolve apenas uma tabela, enquanto um relacionamento binário conecta duas tabelas e um relacionamento ternário envolve três tabelas distintas.
Vamos aprofundar o exemplo com as tabelas “CLIENTE” e “VENDA”. Na tabela “CLIENTE”, encontramos atributos como “ID_Cliente”, “Nome_Cliente” e “CPF”. Esses atributos se relacionam diretamente com a tabela “VENDA”, que, por sua vez, possui seus próprios atributos, como “ID_Venda”, “ID_Cliente”, “ID_Produto” e “Data_Venda”. Essas tabelas estão interligadas através da ação de compra-venda, onde o cliente efetua uma compra e o produto é registrado como vendido. Essa estrutura de banco de dados permite o rastreamento preciso das transações comerciais e a associação das vendas aos clientes correspondentes.
Tabela CLIENTE:
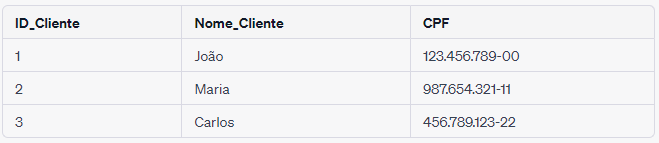
Tabela VENDA:
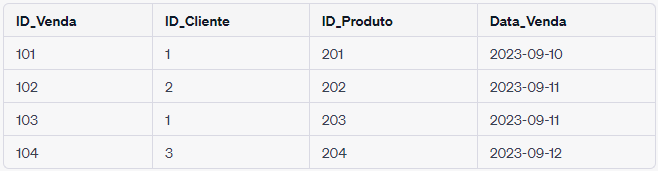
Neste exemplo, a tabela “CLIENTE” contém informações sobre três clientes diferentes, cada um identificado por um “ID_Cliente” único. Os atributos “Nome_Cliente” e “CPF” armazenam os dados pessoais de cada cliente.
Por sua vez, a tabela “VENDA” registra transações de venda. Cada venda é identificada por um “ID_Venda” exclusivo, e a tabela inclui atributos como “ID_Cliente” (que está relacionado com a tabela “CLIENTE”), “ID_Produto” e “Data_Venda”. Por exemplo, na primeira entrada da tabela “VENDA”, a venda com ID_Venda 101 foi realizada pelo cliente com ID_Cliente 1 (João) em 10 de setembro de 2023, envolvendo o produto com ID_Produto 201.
Essas tabelas estão relacionadas através do campo “ID_Cliente”. Isso permite vincular cada venda a um cliente específico na tabela “CLIENTE”, facilitando o rastreamento de quais clientes realizaram quais compras.
Em resumo, os relacionamentos entre tabelas são fundamentais para o funcionamento eficiente de sistemas de gerenciamento de dados, proporcionando uma base sólida para o registro e a análise de informações comerciais e transacionais.
Efetuando Relacionamento entre Múltiplas tabelas
Ao estabelecer relacionamentos entre múltiplas tabelas em um banco de dados, é fundamental seguir algumas práticas essenciais. Primeiramente, cada linha de dados em uma tabela deve ser distinguida de forma única por meio de uma Chave Primária, que serve como um identificador exclusivo. Essa chave é crucial para garantir que cada registro na tabela seja único e facilmente acessível.
Além disso, para conectar dados entre diferentes tabelas, recorremos ao uso de Chaves Estrangeiras. Uma Chave Estrangeira é um campo em uma tabela que se relaciona com a Chave Primária de outra tabela. Isso cria uma ligação direta entre os registros em diferentes tabelas, permitindo que informações sejam compartilhadas e relacionadas de maneira eficaz.
Portanto, a prática comum é estabelecer relacionamentos entre a Chave Primária de uma tabela (que atua como um identificador exclusivo) e a Chave Estrangeira em outra tabela. Esse processo de conexão facilita a busca e a recuperação de dados relacionados, possibilitando um gerenciamento de informações mais eficiente em sistemas de banco de dados complexos.
Chaves
As chaves desempenham um papel fundamental no mundo dos bancos de dados, pois são essenciais para identificar e organizar os dados de maneira eficaz. Uma chave é composta por uma ou mais colunas em uma relação (tabela) que possuem valores únicos usados para identificar exclusivamente uma linha ou um conjunto de linhas dentro dessa tabela.
Existem dois tipos principais de chaves: únicas e não-únicas. As chaves únicas têm a capacidade de identificar uma única linha de forma exclusiva, enquanto as chaves não-únicas podem identificar um conjunto de linhas com base nos valores compartilhados.
Dentro das chaves únicas, temos vários tipos:
1. Chave Candidata: Uma chave candidata é aquela que poderia ser escolhida como a chave primária, pois é única e identifica exclusivamente uma linha. No entanto, pode haver várias chaves candidatas em uma tabela, e apenas uma delas será selecionada como chave primária.
2. Chave Composta: Uma chave composta é criada combinando duas ou mais colunas para formar uma chave única. Isso é útil quando uma única coluna não é suficiente para garantir unicidade.
3. Chave Primária: A chave primária é a chave selecionada como a principal chave de identificação para uma tabela. Ela é única e garante que cada linha seja identificada exclusivamente.
4. Chave Surrogada: Uma chave surrogada é uma chave primária artificial, geralmente um número sequencial, que é introduzido para fins de identificação, independentemente dos dados reais da linha. Isso é útil quando não existe uma chave natural óbvia.
Por outro lado, temos a chave não-única:
1.Chave Estrangeira: A chave estrangeira é usada para estabelecer relacionamentos entre tabelas. Ela não é única e pode ser usada para relacionar registros em uma tabela com os registros em outra tabela usando a chave primária da tabela relacionada.
Em resumo, as chaves desempenham um papel crucial na estruturação e relacionamento de dados em bancos de dados, garantindo a integridade e a eficiência das operações de consulta e manipulação de dados.
Instruções para criação de Chaves Primárias e Estrangeiras
Ao criar chaves primárias e estrangeiras em um banco de dados, é importante seguir algumas diretrizes específicas para garantir a integridade e a eficácia do sistema. Aqui estão algumas instruções essenciais:
Chaves Primárias:
1. Valores Únicos: Uma chave primária não pode conter valores duplicados em uma tabela. Cada valor na coluna da chave primária deve ser exclusivo, garantindo assim a identificação única de cada linha.
2. Imutabilidade: Geralmente, os valores de uma chave primária não devem ser alterados após a inserção inicial dos dados. Isso é importante para manter a integridade dos registros existentes e evitar problemas de identificação.
Chaves Estrangeiras:
1. Ponteiros Lógicos: As chaves estrangeiras são baseadas em valores de dados e podem ser consideradas como “ponteiros lógicos” que estabelecem relacionamentos entre tabelas.
2. Correspondência Obrigatória: Um valor em uma chave estrangeira deve corresponder a um valor existente em uma chave primária associada ou em uma coluna de chave única em outra tabela. Se não houver correspondência, o valor da chave estrangeira pode ser nulo (NULL).
3. Referência à Chave Primária: Uma chave estrangeira deve sempre referenciar uma chave primária ou uma coluna de chave única em outra tabela. Isso garante que os relacionamentos sejam estabelecidos de maneira sólida e que os dados estejam bem estruturados.
Seguir essas instruções ao criar chaves primárias e estrangeiras é fundamental para manter a integridade dos dados, garantir a consistência das informações e permitir que o banco de dados funcione eficazmente em termos de consulta e manipulação de dados.
Domínio
O conceito de “domínio” desempenha um papel fundamental na gestão de dados em bancos de dados e sistemas de informação. Basicamente, o domínio refere-se a dois aspectos cruciais:
1. Definir Tipos de Dados: No contexto do domínio, a definição de tipos de dados é essencial. Isso significa que você precisa especificar o formato ou o tipo de informação que um campo em um banco de dados pode conter. Por exemplo, um campo pode ser do tipo texto, número inteiro, data, entre outros. A escolha do tipo de dados apropriado ajuda a garantir que as informações sejam armazenadas e manipuladas corretamente.
2. Especificar Valores Válidos em um Campo: Além de definir o tipo de dados, o domínio também envolve a especificação de valores válidos para um campo específico. Isso estabelece limites e restrições sobre quais valores podem ser inseridos ou atualizados nesse campo. Por exemplo, um campo que armazena idades pode ter um domínio que restringe os valores a um intervalo específico, como de 0 a 120 anos, para garantir que apenas valores válidos sejam aceitos.
Portanto, o conceito de domínio desempenha um papel crucial na modelagem de dados, ajudando a definir e controlar a natureza dos dados armazenados em um banco de dados, garantindo a precisão e a consistência das informações.
Cardinalidade
O termo “cardinalidade” é essencial no campo de modelagem de dados e se refere à quantidade de itens que se relacionam entre as entidades em um sistema ou banco de dados.
A cardinalidade é uma medida flexível que pode ser dividida em dois aspectos: a cardinalidade máxima e a cardinalidade mínima. A cardinalidade máxima representa o número máximo de instâncias que podem estar associadas em um relacionamento, enquanto a cardinalidade mínima indica o número mínimo de instâncias que devem estar associadas no relacionamento para manter a integridade dos dados.
Por exemplo, em um relacionamento entre uma entidade “Cliente” e uma entidade “Pedido”, a cardinalidade máxima poderia ser “N” para o cliente, indicando que um cliente pode estar associado a vários pedidos (ou nenhum, se for o caso). A cardinalidade mínima poderia ser “1” para o pedido, significando que cada pedido deve estar associado a pelo menos um cliente.
Cardinalidade Máxima
A “cardinalidade máxima” é um conceito fundamental na modelagem de dados, e se refere ao número máximo de instâncias de entidade que podem participar em um relacionamento. Essa cardinalidade máxima pode ser expressa de duas maneiras principais: “1” ou “N” (que representa “muitos”).
Em termos simples, quando a cardinalidade máxima é “1”, isso significa que no relacionamento em questão, cada instância de uma entidade está associada a uma única instância da outra entidade. Em contraste, quando a cardinalidade máxima é “N” (ou “muitos”), isso indica que uma instância de uma entidade pode estar associada a várias instâncias da outra entidade.
Essa definição de cardinalidade máxima é essencial na modelagem de dados, pois ajuda a determinar como as entidades estão relacionadas entre si, quantas conexões podem existir e como os dados podem ser organizados e acessados dentro de um sistema ou banco de dados. É uma parte importante na criação de estruturas de dados eficazes que refletem com precisão as relações do mundo real.
Cardinalidade Mínima
A “cardinalidade mínima” é um conceito crucial na modelagem de dados e refere-se ao número mínimo de instâncias de entidade que são obrigadas a participar em um relacionamento específico. Essa cardinalidade mínima é fundamental para definir o grau de participação que as entidades devem ter no relacionamento.
Basicamente, a cardinalidade mínima pode ser expressa de duas maneiras principais: “zero” (indicando participação opcional) ou “um” (indicando participação obrigatória).
Quando a cardinalidade mínima é “zero”, significa que a participação das entidades no relacionamento é opcional. Ou seja, as instâncias das entidades podem ou não estar associadas a outras instâncias no relacionamento, dependendo das circunstâncias.
Por outro lado, quando a cardinalidade mínima é “um”, isso significa que a participação das entidades no relacionamento é obrigatória. Nesse caso, cada instância da entidade deve estar associada a pelo menos uma instância da outra entidade no relacionamento, não sendo permitido que fique sem uma conexão.
A definição da cardinalidade mínima é fundamental para estabelecer as regras de participação nos relacionamentos, garantindo a consistência dos dados e refletindo com precisão as restrições do mundo real que governam como as entidades interagem em um sistema ou banco de dados.
Simbologia para Cardinalidades
A simbologia para representar as cardinalidades em um diagrama de entidade-relacionamento é essencial para expressar claramente como as entidades estão relacionadas e quantas instâncias de uma entidade estão associadas a outra. A notação de Peter Chen é uma das notações amplamente utilizadas para representar essas cardinalidades.
Notação de Peter Chen:
Aqui estão os símbolos e suas descrições correspondentes:
- (1,1): Representa “Um e Apenas Um”. Isso significa que cada instância da entidade do lado esquerdo do relacionamento está associada a exatamente uma instância da entidade do lado direito. Não há margem para variações.
Entidade A (1,1) ------ Entidade B
Neste caso, cada instância da Entidade A está ligada a uma única instância da Entidade B, e vice-versa.
- (1 .. *): Representa “De Um a Muitos”. Indica que cada instância da entidade do lado esquerdo pode estar associada a várias instâncias da entidade do lado direito, mas pelo menos uma associação é obrigatória.
Entidade A (1 .. *) ------ Entidade B
Isso implica que uma instância da Entidade A pode estar associada a várias instâncias da Entidade B, mas pelo menos uma associação é necessária.
- (0 .. 1): Representa “Zero ou Um”. Indica que cada instância da entidade do lado esquerdo pode estar associada a no máximo uma instância da entidade do lado direito. A associação é opcional.
Entidade A (0 .. 1) ------ Entidade B
Isso implica que uma instância da Entidade A pode estar associada a no máximo uma instância da Entidade B, mas não é obrigatória.
- (0 .. *): Representa “De Zero a Muitos”. Indica que cada instância da entidade do lado esquerdo pode estar associada a várias instâncias da entidade do lado direito, e a associação é opcional.
Entidade A (0 .. *) ------ Entidade B
Isso implica que uma instância da Entidade A pode estar associada a várias instâncias da Entidade B, e não é obrigatória nenhuma associação.
Essa notação fornece uma maneira clara de comunicar as cardinalidades em um diagrama de entidade-relacionamento, ajudando a entender como as entidades estão interconectadas e quais restrições de relacionamento se aplicam.
Simbologia para Cardinalidades (Notação Pé de Galinha)
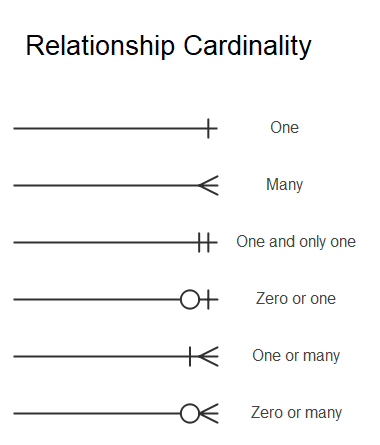
Fonte: https://www.edrawsoft.com/es/article/er-diagrams-for-library-management-system.html
A notação “pé de galinha” é uma convenção visual usada em diagramas de entidade-relacionamento (DER) para representar a cardinalidade em relacionamentos entre entidades. Ela é chamada assim devido à semelhança visual com a pegada de uma galinha.
Na notação “pé de galinha”, os pés de galinha são usados nas extremidades de uma linha que conecta as entidades em um relacionamento. Os pés de galinha contêm números ou símbolos para indicar a cardinalidade mínima e máxima das entidades envolvidas no relacionamento. Por exemplo:
- Um pé de galinha com “1” do lado esquerdo e “M” (representando “muitos”) do lado direito indicaria que uma instância da entidade no lado esquerdo está relacionada com muitas instâncias da entidade no lado direito.
- Um pé de galinha com “0” do lado esquerdo e “1” do lado direito indicaria que uma instância da entidade no lado esquerdo pode estar relacionada com no máximo uma instância da entidade no lado direito.
Essa notação fornece uma representação visual rápida e clara das cardinalidades em um DER, facilitando a compreensão das relações entre as entidades e as restrições associadas a esses relacionamentos.
Exemplo:
No exemplo de cardinalidade abaixo, ilustramos as relações entre as entidades “Cliente” e “Encomenda” por meio de um diagrama e explicamos as cardinalidades mínimas e máximas envolvidas.
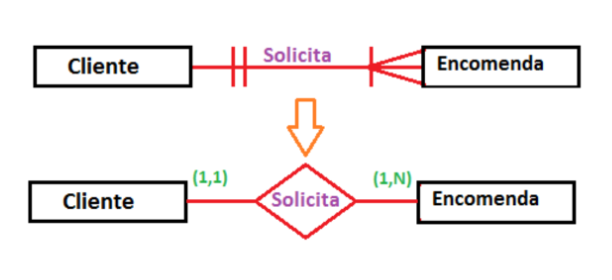
Fonte: https://www.passeidireto.com/arquivo/92800199/2-grau-de-cardinalidade-definicao-e-classificacao
Neste contexto, temos as seguintes informações sobre a cardinalidade:
- Cardinalidade Mínima: Um cliente está associado a, no mínimo, uma encomenda. Isso significa que cada cliente deve ter pelo menos uma encomenda relacionada.
- Cardinalidade Máxima: Um cliente pode estar associado a muitas encomendas. Isso indica que um cliente pode solicitar várias encomendas, sem limite específico.
Em resumo, nesse exemplo, a cardinalidade é lida “de um lado para o outro”. Ou seja, um cliente pode, no mínimo, solicitar uma encomenda (cardinalidade mínima), mas também pode solicitar muitas encomendas (cardinalidade máxima). Da mesma forma, uma encomenda pode ser solicitada por um cliente (cardinalidade mínima) e, no máximo, também por um cliente (cardinalidade máxima).
Essa relação é bidirecional e flexível, permitindo que cada cliente tenha várias encomendas, e cada encomenda seja associada a um único cliente.
Relacionamento Binário (um para um) — 1:1
No contexto de um relacionamento binário um-para-um, estamos tratando de uma situação em que uma instância de entidade única em uma entidade está relacionada a uma instância de entidade única em outra entidade. Para facilitar a compreensão, vamos utilizar um diagrama e exemplos para ilustrar esse conceito:
| Professor |-||----------- Usa -----------||-| Armário |
Neste diagrama, temos duas entidades: “Professor” e “Armário”. Cada professor está associado a um único armário, e cada armário está associado a um único professor. Vamos fornecer alguns exemplos para clarificar isso:
- Professor P1 está relacionado ao Armário A1.
- Professor P2 está relacionado ao Armário A2.
- Professor P3 está relacionado ao Armário A3.
- Professor P4 está relacionado ao Armário A4.
Esses relacionamentos são estritamente um-para-um, o que significa que cada professor tem seu próprio armário exclusivo, e cada armário pertence a um único professor específico. Isso garante que não haja sobreposição ou duplicação de associações entre professores e armários.
Em resumo, no relacionamento binário um-para-um entre Professor e Armário, cada professor possui exatamente um armário, e cada armário pertence a apenas um professor, formando uma relação única e exclusiva entre as entidades.
Relacionamento Binário (um para muitos) — 1:N
o contexto de um relacionamento binário um-para-muitos, estamos tratando de uma situação em que uma instância de entidade única em uma classe de entidade está relacionada a muitas instâncias de entidade em outra classe de entidade. Vamos usar um diagrama e exemplos para ilustrar esse conceito:
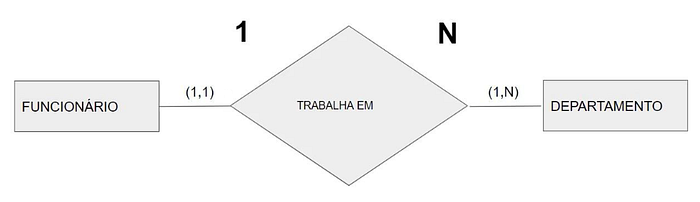
Fonte: https://cursos.alura.com.br/forum/topico-cardinalidade-ao-longo-do-curso-182714
Neste diagrama, temos duas classes de entidade: “Funcionário” e “Departamento”. O relacionamento “Trabalha em” indica que os funcionários estão associados a departamentos.
O relacionamento entre as entidades “Funcionário” e “Departamento” é definido como 1:N, o que significa um para muitos (1:N). Esse tipo de relacionamento implica que um funcionário pode trabalhar em, pelo menos, um departamento, mas no máximo em um departamento. Por outro lado, um departamento pode ter, no mínimo, um funcionário trabalhando e, potencialmente, muitos funcionários (indicado por N) trabalhando nele.
Em resumo, essa relação estabelece que um funcionário é associado a apenas um departamento, enquanto um departamento pode ter diversos funcionários associados a ele, permitindo a flexibilidade de alocação de funcionários em diferentes departamentos, mas garantindo que cada funcionário tenha uma única afiliação departamental.
Relacionamento Binário (muitos para muitos) — N:M
A cardinalidade binária muitos-para-muitos, representada como N:M, é um conceito importante em modelagem de dados que descreve um relacionamento complexo entre duas entidades. Vamos explorar essa cardinalidade usando o exemplo de relacionamento entre “Autor”, “Escreve” e “Livro”.

Fonte: https://slideplayer.com.br/slide/9897292/
Entidades Envolvidas:
- Autor: Representa indivíduos que escrevem livros.
- Escreve: É a associação ou relacionamento que conecta autores a livros.
- Livro: São as obras literárias escritas pelos autores.
Cardinalidade N:M:
Nesse cenário, vários autores podem contribuir para vários livros, e um livro pode ser escrito por múltiplos autores. Isso é uma característica comum na indústria literária, onde diversos autores colaboram em um único livro ou onde um autor pode escrever vários livros. Vamos exemplificar essa cardinalidade com alguns casos:
- O Autor A1 escreve o Livro L1 e também contribui para o Livro L2.
- O Autor A2 escreve apenas o Livro L2.
- O Autor A3 escreve o Livro L1, L2 e L3.
- O Livro L1 é escrito pelos Autores A1 e A3.
- O Livro L3 é escrito somente pelo Autor A3.
Isso ilustra como a cardinalidade N:M permite que vários autores contribuam para vários livros, criando uma rede de relacionamentos complexos. Essa flexibilidade é fundamental para modelar situações da vida real, onde não há limites estritos para o número de autores em um livro ou o número de livros que um autor pode escrever.
Modelagem Adicional:
Em um sistema de gerenciamento de banco de dados, essa cardinalidade N:M geralmente é implementada com uma tabela de junção. Essa tabela de junção armazena pares de chaves estrangeiras que vinculam autores a livros específicos, permitindo uma representação eficaz desse relacionamento complexo.

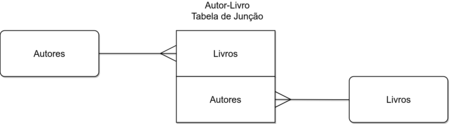
Em resumo, o relacionamento “Autor” “Escreve” “Livro” com cardinalidade N:M demonstra como muitos autores podem estar relacionados a muitos livros, refletindo com precisão as complexidades das colaborações literárias e da autoria múltipla em uma modelagem de dados.
Integridade dos Dados
A integridade de dados é um conceito fundamental na gestão de sistemas de armazenamento de informações. Ela se refere à manutenção e garantia da consistência e precisão dos dados, desempenhando um papel crítico no design, implementação e uso desses sistemas. A integridade dos dados é essencial para assegurar que as informações armazenadas sejam confiáveis e sem erros.
Uma maneira de alcançar a integridade dos dados é por meio da aplicação de restrições de integridade. Essas restrições são regras e condições definidas no sistema de gerenciamento de banco de dados (SGBD) que determinam quais valores são aceitáveis para serem inseridos ou atualizados em um banco de dados. Essas regras podem incluir restrições de chave primária, chave estrangeira, verificação de integridade referencial e outras, dependendo das necessidades do sistema.
O objetivo final da integridade de dados é ter informações precisas e consistentes, sem variações ou corrupções no banco de dados. Isso significa que os dados refletem com precisão a realidade que eles representam e que eles podem ser usados de forma confiável para tomada de decisões e análises. A falta de integridade dos dados pode levar a informações imprecisas e, consequentemente, a decisões erradas.
Portanto, ao projetar e gerenciar sistemas de armazenamento de dados, é crucial dar a devida atenção à integridade dos dados. Isso envolve a definição de restrições apropriadas, a implementação de práticas de validação e a manutenção regular do banco de dados para garantir que ele permaneça livre de corrupções e inconsistências. A integridade de dados é um pilar essencial para a confiabilidade e eficácia de sistemas de informações em diversos contextos, desde empresas até aplicações em larga escala.
Restrições de Integridade
As restrições de integridade são fundamentais para garantir a qualidade e a precisão dos dados em um sistema de armazenamento de informações. Elas desempenham um papel crucial no design e na manutenção de bancos de dados, assegurando que os dados sejam confiáveis e consistentes. Vamos explorar algumas das principais restrições de integridade, incluindo a integridade referencial, a integridade de domínio, a integridade de vazio, a integridade de chave e a integridade definida pelo usuário.
- Integridade de Domínio: Uma restrição de integridade de domínio estabelece que os valores inseridos em uma coluna devem obedecer à definição dos valores permitidos para essa coluna, ou seja, ao domínio dos valores. Por exemplo, se uma coluna armazena preços de mercadorias, apenas valores numéricos são permitidos. Essa restrição leva em consideração fatores como o tipo de dado do campo, a representação interna desse tipo de dado, a presença ou ausência do dado, intervalos de valores no domínio e conjuntos de valores discretos.
- Exemplo de Integridade de Domínio: Para um atributo como “Preço do Produto,” que é do tipo Valor Monetário, valores permitidos incluem 25,33, enquanto valores não permitidos incluem “25 reais e 33 centavos” e “-32,33”.
- Integridade Referencial: A integridade referencial é uma restrição que garante que os valores em uma coluna de uma tabela sejam válidos com base nos valores em outra tabela relacionada. Por exemplo, se um produto de ID 523 é cadastrado em uma tabela de Vendas, um produto com ID 523 deve existir na tabela de Produtos relacionada. Caso contrário, ocorrerá uma violação da integridade de referência.
- Exemplo de Integridade Referencial: Para um atributo como “Nome_Produto,” apenas valores que correspondem a produtos cadastrados na tabela de produtos são permitidos. “Cerveja,” que não existe na tabela de produtos, é um exemplo de valor não permitido.
- Integridade de Chave: Essa restrição exige que os valores inseridos na coluna de chave primária (PK) sejam sempre únicos e não admitam repetições. Isso garante que cada tupla (registro) seja distinta e que a chave primária não contenha valores nulos.
- Integridade de Vazio: A integridade de vazio indica se uma coluna é obrigatória ou opcional, ou seja, se é possível não inserir um valor na coluna. Por exemplo, uma coluna de chave primária deve sempre conter dados e nunca pode estar vazia, enquanto uma coluna opcional pode aceitar valores nulos.
- Valores Nulos (NULL): Valores nulos indicam a ausência de dados e são diferentes de zero, espaço em branco ou uma string vazia. Eles podem ser problemáticos, pois podem indicar que o valor da coluna não é apropriado, que o valor não foi inserido ou que o valor é desconhecido.
- Integridade Definida pelo Usuário: Essa integridade refere-se a regras de negócio específicas definidas pelo usuário do banco de dados. Por exemplo, um usuário pode definir que uma coluna só aceitará um conjunto restrito de valores, personalizando as restrições com base nas necessidades do sistema.
Em resumo, as restrições de integridade são elementos essenciais para manter a qualidade e a precisão dos dados em um banco de dados. Elas são aplicadas para garantir que os dados estejam de acordo com as regras definidas e as necessidades do sistema, contribuindo para a confiabilidade e a consistência das informações armazenadas.
Dicionário de Dados
Um dicionário de dados é um recurso valioso no contexto da administração de bancos de dados. Ele é um documento que tem como finalidade registrar informações detalhadas sobre o conteúdo, o formato e a estrutura de um banco de dados, além de documentar os relacionamentos entre seus diversos elementos. Em outras palavras, o dicionário de dados age como um guia abrangente que fornece informações essenciais sobre como os dados estão organizados e como podem ser acessados no banco de dados.
Manter um dicionário de dados é de suma importância ao criar e gerenciar um banco de dados, pois ajuda a evitar erros e garantir a consistência na estrutura física do banco de dados no ambiente de computação. Ao documentar as tabelas, campos, tipos de dados, restrições e relacionamentos, os desenvolvedores e administradores de banco de dados podem ter uma visão clara do que está contido no banco de dados e como os elementos estão interconectados.
Além disso, o dicionário de dados é frequentemente referido como um “Repositório de Metadados” porque contém informações sobre os próprios dados, tornando-se uma ferramenta valiosa para a gestão dos metadados, ou seja, os dados sobre os dados. Esses metadados incluem descrições detalhadas dos elementos do banco de dados, como nomes, definições, formatos, chaves primárias e estrangeiras, entre outros aspectos cruciais.
Em resumo, um dicionário de dados desempenha um papel fundamental na organização e na manutenção de bancos de dados, fornecendo um recurso central para documentar e entender a estrutura e o conteúdo dos dados, minimizando erros e promovendo a consistência na gestão de informações. É uma ferramenta essencial para qualquer equipe que trabalhe com bancos de dados, desde desenvolvedores até administradores de sistemas.
Dependências
Dependência Funcional
No campo da modelagem de dados e gerenciamento de bancos de dados, é fundamental compreender o conceito de dependências e, mais especificamente, a dependência funcional. Esses conceitos nos ajudam a entender como os atributos de uma entidade ou tabela estão relacionados e influenciam uns aos outros.
Primeiramente, vamos abordar o conceito de dependências em um contexto mais amplo. Dependências referem-se às relações entre diferentes atributos de uma entidade ou tabela. Quando dizemos que um atributo depende de outro, estamos estabelecendo uma conexão que indica que as informações contidas em um atributo podem ser determinadas com base nas informações do outro.
A dependência funcional é uma forma específica de dependência que ocorre quando um atributo, chamado de “dependente,” é funcionalmente determinado por outro atributo, chamado de “determinante.” Essa relação é simbolizada da seguinte forma:
X -------> Y
Lemos isso como “X determina funcionalmente Y.” Significa que, para cada valor de X, há exatamente um valor correspondente de Y. Isso implica que o valor de Y depende diretamente do valor de X.
Exemplo Prático: Prazo de Entrega de um Pedido
Vamos ilustrar essa ideia com um exemplo concreto. Considere uma entidade chamada “Pedido” com dois atributos: “Número do Pedido” e “Prazo de Entrega do Pedido.” Neste caso, podemos afirmar que o prazo de entrega do pedido depende funcionalmente do número do pedido:
Numero_Pedido -----> Prazo_Entrega_Pedido
Isso significa que, para cada número de pedido específico, há um prazo de entrega correspondente, e vice-versa. O número do pedido atua como o determinante, e o prazo de entrega do pedido é o atributo dependente.
Importância na Modelagem de Dados:
A compreensão das dependências funcionais é essencial na modelagem de dados. Uma chave primária em uma relação, por exemplo, determina funcionalmente todos os outros atributos não-chave na linha. Isso significa que a chave primária desempenha um papel crítico na organização e na recuperação de dados em um banco de dados, uma vez que seus valores únicos garantem a identificação exclusiva de cada registro.
Em resumo, as dependências funcionais são uma parte fundamental da modelagem de dados, ajudando a estabelecer relações claras entre atributos em uma entidade ou tabela. Compreender essas dependências é essencial para o design adequado de bancos de dados e para garantir a integridade e a precisão das informações armazenadas.
Dependência Funcional Total
A dependência funcional total é um conceito importante na modelagem de dados, especialmente quando lidamos com relações que possuem chaves primárias compostas. Ela ocorre quando um atributo não-chave depende de toda a chave primária, e não apenas de parte dela. Vamos entender melhor esse conceito com um exemplo prático e uma representação visual.
Considere uma relação chamada “Item-Pedido” que representa os itens individuais de pedidos em um sistema. Nessa relação, temos uma chave primária composta que consiste em dois atributos: “Num_Pedido” e “Cod_Produto”. Além disso, temos o atributo “Quant_Produto”, que representa a quantidade de produtos em um item de pedido.
Aqui está uma representação visual dessa relação:
Item-Pedido
------------------------
| PK | Num_Pedido | <---|
------------------------ |
| PK | Cod_Produto | <---| --> Dependência total
------------------------ |
| | Quant_Produto | ---|
------------------------
Agora, vamos analisar a dependência funcional total nesse contexto:
- A dependência funcional total ocorre quando o atributo “Quant_Produto” depende tanto de “Num_Pedido” quanto de “Cod_Produto” simultaneamente. Isso significa que, para determinar a quantidade de um produto em um item de pedido, é necessário conhecer tanto o número do pedido quanto o código do produto. Esses dois valores em conjunto são essenciais para obter a informação completa sobre a quantidade do produto em questão.
Isso pode ser representado da seguinte forma:
Num_Pedido, Cod_Produto -----> Quant_Produto
Nesse diagrama, a seta indica que “Num_Pedido” e “Cod_Produto” determinam funcionalmente o valor de “Quant_Produto” de forma conjunta. Portanto, podemos dizer que “Quant_Produto” possui uma dependência funcional total em relação à chave primária composta (“Num_Pedido” e “Cod_Produto”).
Em resumo, a dependência funcional total é um conceito relevante quando atributos dependem não apenas de parte, mas de toda a chave primária de uma relação. Ela destaca a importância das relações de dados e como os atributos se relacionam de forma precisa para fornecer informações completas e corretas no contexto de bancos de dados.
Dependência Funcional Parcial
A dependência funcional parcial é um conceito importante na modelagem de dados que se aplica quando os atributos não-chave de uma tabela não dependem funcionalmente de toda a chave primária, especialmente quando essa chave primária é composta. Em outras palavras, ocorre uma dependência funcional, mas apenas de uma parte da chave primária.
Vamos ilustrar esse conceito com um exemplo prático. Considere uma tabela chamada “Matrículas” que registra informações sobre matrículas de alunos em disciplinas. Nessa tabela, temos três atributos principais: “ID_Aluno,” “Cod_Disciplina,” “Nome_Disciplina” e “Data_Inicio.” A chave primária é composta por “ID_Aluno” e “Cod_Disciplina.”
Aqui está uma representação visual dessa tabela:
Matrículas
-----------------------
| PK | ID_Aluno |
-----------------------
| PK | Cod_Disciplina | <----|
----------------------- | --> Dependência parcial
| | Nome_Disciplina| ____|
-----------------------
| | Data_Inicio |
-----------------------
A dependência funcional parcial ocorre no contexto da relação entre “Cod_Disciplina” e “Nome_Disciplina.” Nesse cenário, o atributo “Nome_Disciplina” depende funcionalmente do “Cod_Disciplina,” mas não depende do “ID_Aluno.” Em outras palavras, o nome da disciplina está relacionado ao código da disciplina, mas não está vinculado ao identificador do aluno. Isso significa que o aluno pode estar matriculado em várias disciplinas, e o nome da disciplina permanece o mesmo para um código de disciplina específico, independentemente do aluno.
Essa dependência parcial ressalta a complexidade das relações em bancos de dados e a importância de identificar como os atributos se relacionam dentro de uma tabela. Isso também destaca como a chave primária composta pode levar a diferentes tipos de dependências funcionais, dependendo dos atributos envolvidos.
Em resumo, a dependência funcional parcial é um conceito crucial na modelagem de dados que ocorre quando os atributos não-chave dependem apenas de uma parte da chave primária composta, demonstrando como os atributos se relacionam de maneira precisa e específica em um banco de dados.
Dependência Funcional Transitiva
A dependência funcional transitiva é um conceito importante em bancos de dados que ocorre quando um campo não depende diretamente da chave primária da tabela, nem mesmo parcialmente, mas depende de outro campo que não é uma chave primária.
Vamos ilustrar esse conceito com um exemplo prático. Considere uma tabela chamada “Pedido,” que registra informações sobre pedidos de produtos. Nessa tabela, temos quatro atributos principais: “Num_Pedido,” “Prazo_Entrega,” “Cod_Vendedor” e “Nome_Vendedor.” A chave primária é “Num_Pedido,” e “Cod_Vendedor” é uma chave estrangeira que se relaciona com outra tabela.
Aqui está uma representação visual dessa tabela:
Pedido
-----------------------
| PK | Num_Pedido |
-----------------------
| | Prazo_Entrega |
-----------------------
| FK | Cod_Vendedor | <---|
----------------------- | --> Dependência funcional transitiva
| | Nome_Vendedor | ____|
-----------------------
A dependência funcional transitiva ocorre no contexto da relação entre “Nome_Vendedor” e “Cod_Vendedor.” Nesse cenário, o atributo “Nome_Vendedor” depende funcionalmente do “Cod_Vendedor,” que não é uma chave primária na tabela. Em outras palavras, o nome do vendedor está relacionado ao código do vendedor, mas não está diretamente vinculado à chave primária, “Num_Pedido.”
Isso significa que a dependência funcional transitiva ocorre quando um campo não depende diretamente da chave primária, mas sim de outro campo não-chave. No exemplo dado, o campo “Prazo_Entrega” depende da chave primária “Num_Pedido,” mas o campo “Nome_Vendedor” depende do campo não-chave “Cod_Vendedor.”
Essa dependência transitiva ressalta a complexidade das relações de dados em bancos de dados e como os atributos podem estar interconectados de maneira indireta, por meio de outros campos. É fundamental identificar e compreender essas dependências para projetar e gerenciar eficazmente bancos de dados.
Em resumo, a dependência funcional transitiva é um conceito relevante na modelagem de dados que ocorre quando um campo não depende diretamente da chave primária da tabela, mas sim de outro campo não-chave, ilustrando a complexidade das relações de dados em bancos de dados.
Dependência Multivalorada
A dependência multivalorada é um conceito essencial na modelagem de dados que ocorre quando, para cada valor de um atributo A, existe um conjunto de valores para outros atributos B e C que estão associados a ele, mas são independentes entre si. Essa dependência é representada da seguinte forma:
A ->> B
Onde B é a coluna que depende de A
Nesse formato, “A” é o atributo que atua como determinante, enquanto “B” é a coluna que depende de “A”. Vamos ilustrar esse conceito com um exemplo prático: Considere uma tabela que armazena informações sobre carros, incluindo os atributos “Modelo,” “Ano,” e “Cor.” Aqui está uma representação simplificada dessa tabela:
Modelo | Ano | Cor
------------------------------
Gol | 2016 | Prata
------------------------------
Uno | 2016 | Preto
------------------------------
Uno | 2015 | Prata
------------------------------
Fox | 2016 | Vermelho
------------------------------
Fox | 2014 | Branco
- Ano e Cor são independentes entre si e dependem do modelo do carro.
- Essas duas colunas são dependentes multivaloradas do Modelo
Nesse contexto, podemos observar uma dependência multivalorada. Os atributos “Ano” e “Cor” são independentes entre si, ou seja, o ano de fabricação de um carro não está diretamente relacionado com a cor dele, e vice-versa. No entanto, ambos esses atributos dependem do atributo “Modelo” do carro. Portanto, podemos dizer que “Ano” e “Cor” são dependentes multivaloradas do “Modelo.”
Essa dependência multivalorada destaca como os atributos em um banco de dados podem estar interconectados de maneira complexa. Ela é importante de ser reconhecida na modelagem de dados, pois afeta a estrutura das tabelas e como os dados são organizados e acessados.
Em resumo, a dependência multivalorada ocorre quando vários atributos estão associados a um determinado valor de um atributo principal, mas esses atributos secundários são independentes entre si. Ela é representada pela seta “->>” e desempenha um papel crucial na definição das relações de dados em um banco de dados.
Normalização e Anomalias
A normalização é um processo fundamental no design de bancos de dados, que visa eliminar anomalias, problemas que podem surgir em bancos de dados mal planejados e não normalizados, muitas vezes devido ao excesso de dados armazenados em uma única tabela. Essas anomalias são frequentemente causadas por dependências parciais e transitivas entre os atributos das tabelas.
As anomalias de atualização são um tipo específico de anomalia que pode ocorrer quando se modifica o conteúdo de um banco de dados. Elas são classificadas em três tipos principais: anomalias de inserção, de exclusão e de modificação.
- Anomalia de Inclusão: Este tipo de anomalia ocorre quando não é possível adicionar um novo dado a menos que outro dado relacionado esteja disponível. Por exemplo, não deve ser permitido cadastrar um novo livro no banco de dados sem que um autor já esteja cadastrado. Isso garante que cada livro tenha um autor associado.
- Anomalia de Exclusão: As anomalias de exclusão surgem quando ao excluir um registro de uma tabela, dados relacionados em outras tabelas também são excluídos. Por exemplo, se excluirmos um autor, os livros escritos por esse autor também devem ser excluídos. Essa integridade garante que os dados relacionados permaneçam consistentes.
- Anomalia de Modificação: Esse tipo de anomalia ocorre quando uma modificação em um dado em uma tabela requer a alteração de dados em outras tabelas para manter a integridade referencial. Por exemplo, se o código de um autor for modificado, esse código deve ser alterado na tabela de autores e também na tabela de livros para manter o relacionamento entre livros e seus autores correto.
Para eliminar essas anomalias e garantir a integridade dos dados, é necessário projetar os esquemas de relações (tabelas) no banco de dados de forma que nenhuma anomalia de inserção, exclusão ou modificação esteja presente nas relações. Esse processo de organização é conhecido como normalização. A normalização divide as tabelas em estruturas mais simples e relacionadas, reduzindo assim a duplicação de dados e garantindo a consistência dos dados.
Em resumo, as anomalias de atualização são problemas que podem surgir em bancos de dados mal projetados, mas podem ser eliminados por meio da normalização. Esse processo ajuda a manter a integridade e a consistência dos dados, evitando problemas potenciais nas operações de inserção, exclusão e modificação. Portanto, a normalização desempenha um papel crucial na criação de bancos de dados eficientes e confiáveis.
Normalização
A normalização é um processo crucial na área de banco de dados, com o objetivo de garantir que uma relação (tabela) seja bem estruturada, livre de anomalias e redundâncias. Este processo envolve a decomposição de relações que possuem anomalias em relações menores e mais organizadas. O resultado é que em uma relação normalizada, podemos inserir, excluir ou modificar registros sem criar anomalias indesejadas.
O conceito de normalização foi proposto por Edgar F. Codd em 1972, e desde então, tem sido uma parte fundamental do design de bancos de dados relacionais. Codd inicialmente apresentou três formas normais: 1ª, 2ª e 3ª formas normais (1FN, 2FN e 3FN). Mais tarde, a 3FN foi aprimorada e recebeu uma definição mais robusta, conhecida como Forma Normal de Boyce-Codd (FNBC).
Os objetivos da normalização incluem:
1. Minimizar Redundâncias: A normalização visa reduzir a duplicação de dados em um banco de dados, garantindo que as informações sejam armazenadas de forma eficiente, sem repetições desnecessárias. Isso economiza espaço de armazenamento e mantém a consistência dos dados.
2. Minimizar Anomalias de Inserção, Exclusão e Modificação: As anomalias podem ocorrer quando inserimos, excluímos ou modificamos dados em uma relação. A normalização ajuda a eliminar essas anomalias, garantindo que as operações no banco de dados ocorram sem problemas e sem efeitos colaterais indesejados.
3. Decomposição de Relações: Para alcançar esses objetivos, as relações são decompostas em esquemas de relações menores que atendem aos critérios de formas normais específicas. O objetivo final é alcançar a Forma Normal de Boyce-Codd (FNBC) ou a 3ª Forma Normal (3FN) para cada tabela do banco de dados.
É importante observar que a normalização não deve parar na 1FN ou 2FN, pois essas formas normais são usadas como etapas intermediárias para atingir a 3FN ou FNBC. O foco é sempre alcançar um estado em que a estrutura do banco de dados seja altamente organizada, eficiente e livre de problemas potenciais.
Em resumo, a normalização é um processo essencial no design de banco de dados relacionais, com o objetivo de criar estruturas bem organizadas e livres de anomalias e redundâncias. Isso é alcançado por meio da decomposição de relações em esquemas menores e bem estruturados, seguindo as formas normais estabelecidas por Codd e aprimoradas por outros, como a Forma Normal de Boyce-Codd (FNBC). O resultado final é um banco de dados eficiente e confiável.
Primeira Forma Normal
A Primeira Forma Normal (1FN) é um conceito fundamental na normalização de bancos de dados relacionais, historicamente definido para eliminar atributos multivalorados, compostos e suas combinações. O objetivo principal da 1FN é garantir que os dados estejam organizados de forma que o domínio de um atributo contenha apenas valores atômicos, ou seja, valores que não possam ser subdivididos em partes menores. Além disso, cada atributo em uma tupla (linha) deve conter um único valor que pertença ao domínio desse atributo.
Uma tabela é considerada estar na 1FN quando atende aos seguintes critérios:
1. Valores Atômicos: Todos os valores presentes na tabela devem ser atômicos, ou seja, não podem ser divididos em partes menores. Isso implica que não devem existir atributos multivalorados ou relações aninhadas na tabela.
2. Não há Grupos de Atributos Repetidos: Cada coluna na tabela deve conter apenas um dado por linha, eliminando assim grupos de atributos repetidos.
3. Chave Primária: Deve existir uma chave primária que identifique exclusivamente cada linha na tabela.
Atomicidade dos Dados
Dados atômicos são elementos de dados que representam o nível mais baixo de detalhamento. São informações que não podem ser subdivididas sem perder seu significado. Por outro lado, campos não atômicos são aqueles que podem ser divididos em partes menores, escondendo detalhes. Por exemplo, um campo de “Nome” em uma tabela pode conter tanto o primeiro nome quanto o sobrenome, o que tornaria o campo não atômico.
Para ilustrar o conceito de dados atômicos e a importância da 1FN, considere o campo de “Endereço” que normalmente contém informações sobre a rua, número e CEP. Para atender à 1FN, esses elementos devem ser separados em campos diferentes, cada um representando um valor atômico. Dessa forma, a tabela estará bem estruturada e em conformidade com a Primeira Forma Normal.
Em resumo, a Primeira Forma Normal (1FN) é essencial para garantir que os dados em um banco de dados estejam bem organizados e sem ambiguidades. Ela exige que os valores sejam atômicos, não haja grupos de atributos repetidos, exista uma chave primária e não haja atributos multivalorados ou relações aninhadas. Isso permite uma estrutura de dados clara e consistente.
Segunda Forma Normal
A Segunda Forma Normal (2FN) é um conceito importante no design de bancos de dados relacionais e baseia-se no princípio de Dependência Funcional Total. Um esquema de relação R é considerado estar na 2FN quando cada atributo não-chave de R for funcionalmente dependente de forma total da chave primária (PK) de R.
Para verificar se uma tabela está na 2FN, realizamos os seguintes testes:
1. Primeira Forma Normal (1FN): A tabela deve estar na 1FN, o que significa que todos os valores devem ser atômicos, não pode haver grupos de atributos repetidos, deve existir uma chave primária e não pode haver atributos multivalorados ou relações aninhadas.
2. Dependência Funcional Total: Todos os atributos não-chave da tabela devem ser funcionalmente dependentes de todas as partes da chave primária. Isso significa que cada atributo não-chave deve depender de toda a chave primária, não apenas de parte dela.
3. Ausência de Dependências Parciais: Não devem existir dependências parciais na tabela. Dependências parciais ocorrem quando um atributo não-chave depende apenas de uma parte da chave primária, e isso não é permitido na 2FN.
Se a tabela atender a todos esses critérios, ela estará na 2FN. Caso contrário, será necessário criar novas tabelas para atender aos requisitos da 2FN. Para fazer isso:
- Crie uma nova relação para cada chave primária ou combinação de atributos que são determinantes em uma dependência funcional.
- O atributo que é determinante em uma dependência funcional será a chave primária na nova tabela.
- Mova os atributos não-chave que são dependentes dessa chave primária para a nova tabela.
O objetivo da Segunda Forma Normal é garantir que os dados estejam bem estruturados e sem anomalias de dependência funcional parcial. Ao seguir essas diretrizes, projetistas de banco de dados podem criar um esquema de relação eficiente e coerente, proporcionando uma base sólida para consultas e operações de banco de dados.
Terceira Forma Normal
A Terceira Forma Normal (3FN) é um conceito fundamental no design de bancos de dados relacionais, baseado no princípio de Dependência Transitiva. Uma tabela ou esquema de relação R está na 3FN quando não existem atributos não-chave que sejam determinados funcionalmente por outros atributos não-chave ou conjuntos de atributos. Isso significa que não deve haver dependência transitiva de um atributo não-chave em relação à chave primária (PK).
Para uma tabela estar na 3FN, ela deve atender aos seguintes critérios:
1. Segunda Forma Normal (2FN): A tabela deve estar na 2FN, o que significa que todos os atributos não-chave devem ser funcionalmente dependentes de todas as partes da chave primária. A 2FN elimina dependências parciais e garante que cada atributo não-chave dependa da chave primária como um todo.
2. Ausência de Dependências Transitivas: Não deve haver dependências transitivas em que um atributo não-chave depende funcionalmente de outro atributo não-chave. Ou seja, nenhum atributo não-chave deve ser determinado por outro atributo não-chave.
Para alcançar a 3FN, o processo envolve a decomposição da tabela e a criação de novas tabelas que incluem os atributos não-chave que determinam funcionalmente outros atributos não-chave. O atributo que é um determinante na relação será a chave primária (PK) na nova tabela. Todos os atributos que são dependentes funcionalmente desse determinante serão movidos para a nova tabela. Além disso, o atributo que se tornou a PK na nova relação permanecerá na tabela original e servirá como uma chave estrangeira para estabelecer a associação entre as duas relações.
A Terceira Forma Normal é essencial para garantir que os dados estejam bem estruturados, sem anomalias de dependência transitiva. Ao seguir essas diretrizes, os projetistas de banco de dados podem criar esquemas de relação que são eficientes e promovem a integridade dos dados, permitindo consultas e operações de banco de dados mais eficazes.
Os passos da Normalização
A normalização de um banco de dados é um processo fundamental no design de esquemas de relação que buscam a eficiência, integridade e consistência dos dados. Ela é dividida em várias etapas, cada uma das quais tem o objetivo de eliminar anomalias e garantir que os dados estejam organizados da melhor forma possível.
Os passos da normalização são conduzidos de forma sequencial, começando com uma tabela não-normalizada. Aqui estão os passos-chave da normalização:
1. Tabela Não-Normalizada: O processo começa com uma tabela que não está em conformidade com os princípios de normalização. Esta tabela pode conter redundâncias, dependências funcionais parciais e transitivas, bem como atributos multivalorados e compostos.
2. Primeira Forma Normal (1FN): O primeiro passo é eliminar atributos multivalorados e compostos. Isso envolve dividir os valores em atributos atômicos individuais e garantir que não haja grupos de atributos repetidos em uma mesma linha. A tabela resultante deve estar na 1FN.
3. Segunda Forma Normal (2FN): Após a 1FN, o próximo passo é remover as dependências funcionais parciais, garantindo que todos os atributos não-chave dependam funcionalmente de todas as partes da chave primária. A tabela agora estará na 2FN.
4. Terceira Forma Normal (3FN): O último passo é eliminar as dependências funcionais transitivas, garantindo que não haja atributos não-chave que dependam funcionalmente de outros atributos não-chave. Isso leva a uma tabela que está na 3FN.
Tabela
Não-Normalizada \
\
Remover atributos
Multivalorados e Compostos
\
\ 1ªFN
Remover Dependências
Parciais (se existirem)
\
\ 2ªFN
Remover Dependências
Transitivas
/
/
3ªFN (sua tabela já estará basicamente
pronta para ser implementada em um BD fisicamente)
Ao concluir esses passos, a tabela estará basicamente pronta para ser implementada fisicamente em um banco de dados. A normalização tem como objetivo eliminar redundâncias e anomalias, promovendo a consistência e a integridade dos dados. Cada forma normal alcançada representa um nível mais alto de organização e eficiência dos dados, tornando-os mais adequados para consulta e manipulação em um sistema de gerenciamento de banco de dados.
Forma Normal de Boyce-Codd
A Forma Normal de Boyce-Codd (FNBC) é uma extensão da Terceira Forma Normal (3FN) que lida especificamente com situações em que uma tabela possui várias chaves candidatas compostas e superpostas, o que a definição original da 3FN de Codd não abordava adequadamente.
A definição original da 3FN de Codd é suficiente para a maioria das tabelas, mas ela não tratava eficazmente de casos em que uma tabela atendia às seguintes condições:
1. Tinha duas ou mais chaves candidatas.
2. Essas chaves candidatas eram compostas, ou seja, consistiam em múltiplos atributos.
3. Essas chaves candidatas tinham superposição, ou seja, compartilhavam alguns atributos em comum.
Em situações em que essas condições ocorrem em uma tabela, é necessário aplicar a Forma Normal de Boyce-Codd para evitar anomalias e garantir a integridade dos dados.
Os princípios da Forma Normal de Boyce-Codd são os seguintes:
- Uma relação está na FNBC se e somente se os únicos determinantes de seus atributos são chaves candidatas.
- Cada relação na FNBC também está na 3FN, mas o contrário nem sempre é verdadeiro (ou seja, uma relação na 3FN nem sempre está na FNBC).
- Quando uma tabela possui mais de uma chave candidata, é possível que ocorram anomalias, como dependências parciais por outros atributos.
- Na FNBC, as chaves candidatas não possuem dependências parciais em relação a outros atributos.
- Uma relação R está na FNBC sempre que uma dependência funcional não trivial X → A se mantiver em R, indicando que X é uma superchave de R.
Em resumo, a Forma Normal de Boyce-Codd é uma extensão da normalização que lida com tabelas complexas que possuem múltiplas chaves candidatas compostas e superpostas, garantindo que essas tabelas estejam bem estruturadas e livres de anomalias de dependência funcional.
Pontos a considerar sobre a Forma Normal de Codd
Na Forma Normal de Boyce-Codd (FNBC), existem alguns pontos importantes a serem considerados para entender as dependências funcionais e garantir a integridade dos dados:
- Determinante: O determinante é o “lado esquerdo” de uma Dependência Funcional (DF). Em uma DF do tipo X → Y, o X é o determinante, e ele determina funcionalmente o valor de Y. Isso significa que o valor de Y depende do valor de X.
- Dependência Funcional Trivial: Uma Dependência Funcional é considerada trivial quando ela é tão óbvia que não pode deixar de ser satisfeita. Em outras palavras, uma DF é trivial quando o lado direito da expressão é um subconjunto do lado esquerdo. Por exemplo, se tivermos a DF {ID_Func, Nome_Func} → ID_Func, essa é uma DF trivial, pois ID_Func é um subconjunto de {ID_Func, Nome_Func}.
Esses conceitos são fundamentais para a compreensão das dependências funcionais na FNBC. Eles nos ajudam a identificar quais dependências são essenciais para a estrutura da tabela e quais são tão óbvias que não precisam ser especificadas separadamente. A compreensão desses pontos é crucial para projetar e normalizar efetivamente um banco de dados.
Definindo
Na relação FORN, que contém os atributos F#, F_Nome, P#, e Qtde, identificamos as seguintes chaves candidatas: {F#, P#} e {F_Nome, P#}. Essas chaves candidatas são combinações únicas de atributos que podem ser usadas para identificar exclusivamente cada tupla na tabela.
Aqui está um exemplo parcial da tabela FORN:
FORN
--------------------------------------
F# | F_Nome | P# | Qtde
--------------------------------------
F1 | Acme | P1 | 600
--------------------------------------
F1 | Acme | P2 | 300
--------------------------------------
F1 | Acme | P3 | 250
--------------------------------------
F1 | Acme | P4 | 280
--------------------------------------
F2 | Umbrella | P1 | 350
--------------------------------------
... | ... | ... | ...
Nesta representação parcial da tabela FORN, você pode ver como as combinações dos atributos F# e P# ou F_Nome e P# são únicas para cada tupla. Essas combinações formam as chaves candidatas da tabela e são usadas para garantir a unicidade dos registros na relação FORN. Isso é fundamental para manter a integridade dos dados e permitir operações de consulta e modificação precisas no banco de dados.
FNBC — Normalizando
Para normalizar uma tabela até a Forma Normal de Boyce-Codd (FNBC), é necessário seguir um processo de decomposição da tabela. Os passos para realizar essa decomposição são os seguintes:
1. Encontrar uma Dependência Funcional não-trivial X → Y que viole a condição da FNBC. É importante observar que X não deve ser uma superchave na tabela. Em outras palavras, estamos procurando uma dependência entre atributos não relacionados à chave primária da tabela que não possa ser derivada de forma trivial.
2. Dividir a tabela em duas novas tabelas:
- Uma tabela que conterá os atributos XY, ou seja, todos os atributos envolvidos na dependência funcional encontrada no passo anterior.
- Outra tabela que conterá os atributos X, juntamente com os atributos restantes da tabela original que não fazem parte da dependência funcional.
Esse processo de decomposição visa eliminar as dependências funcionais não triviais que violam a FNBC, garantindo que cada tabela resultante esteja na FNBC. A ideia é criar tabelas que sejam mais simples e independentes em termos de dependências funcionais, o que contribui para a integridade e a organização dos dados no banco de dados.
Finalizando…
A modelagem de dados e o design de bancos de dados são elementos cruciais na construção de sistemas de informação eficientes e robustos. Neste artigo, exploramos os principais conceitos relacionados a essas práticas fundamentais.
Começamos abordando a importância da modelagem de dados, destacando como ela permite a representação clara e estruturada das informações que um sistema de banco de dados precisa armazenar e gerenciar. Discutimos os diferentes tipos de modelos de dados, desde o modelo conceitual até o modelo físico, e como eles se relacionam para criar uma representação completa do domínio de dados de um sistema.
Em seguida, exploramos o processo de criação e design de bancos de dados. Discutimos como identificar requisitos de negócios, definir entidades, atributos e relacionamentos, e aplicar regras de normalização para garantir a integridade e a eficiência dos dados. Abordamos também as restrições de integridade, as chaves primárias e estrangeiras, e como elas são fundamentais para manter a consistência dos dados.
Ao longo do artigo, examinamos exemplos práticos e utilizamos diagramas para ilustrar os conceitos apresentados. Discutimos a importância de se evitar anomalias de dados e como a normalização ajuda a alcançar esse objetivo.
Finalmente, destacamos a importância da Forma Normal de Boyce-Codd (FNBC) como um objetivo de normalização, e como a decomposição de tabelas pode ser usada para alcançar esse padrão.
Em resumo, a modelagem de dados e o design de bancos de dados são elementos essenciais para o sucesso de qualquer projeto de desenvolvimento de software. Com uma modelagem sólida e um design bem pensado, podemos garantir que nossos sistemas sejam capazes de armazenar, acessar e manipular dados de forma eficiente e confiável, contribuindo para o sucesso de nossos projetos e organizações.
Portanto, ao enfrentar desafios relacionados a bancos de dados, lembre-se da importância de uma modelagem cuidadosa e de um design bem planejado.
Referências:
Mapeamento para esquema lógico
Grau de Cardinalidade: Definição e classificação



