
# 🚀 Do Erro 500 ao Sucesso
- #Docker
- #Python
- #Markdown
- #IA Generativa
 # 🚀 Como Construí e Atualizei um Motor de RAG e Governança com FastAPI, Streamlit e Gemini 2.5
# 🚀 Como Construí e Atualizei um Motor de RAG e Governança com FastAPI, Streamlit e Gemini 2.5
Construir aplicações baseadas em Inteligência Artificial Generativa vai muito além de dar um "prompt" no chat. No mundo real, a engenharia de software exige arquiteturas robustas, pipelines de dados eficientes e resiliência para lidar com as constantes atualizações de modelos das Big Techs.
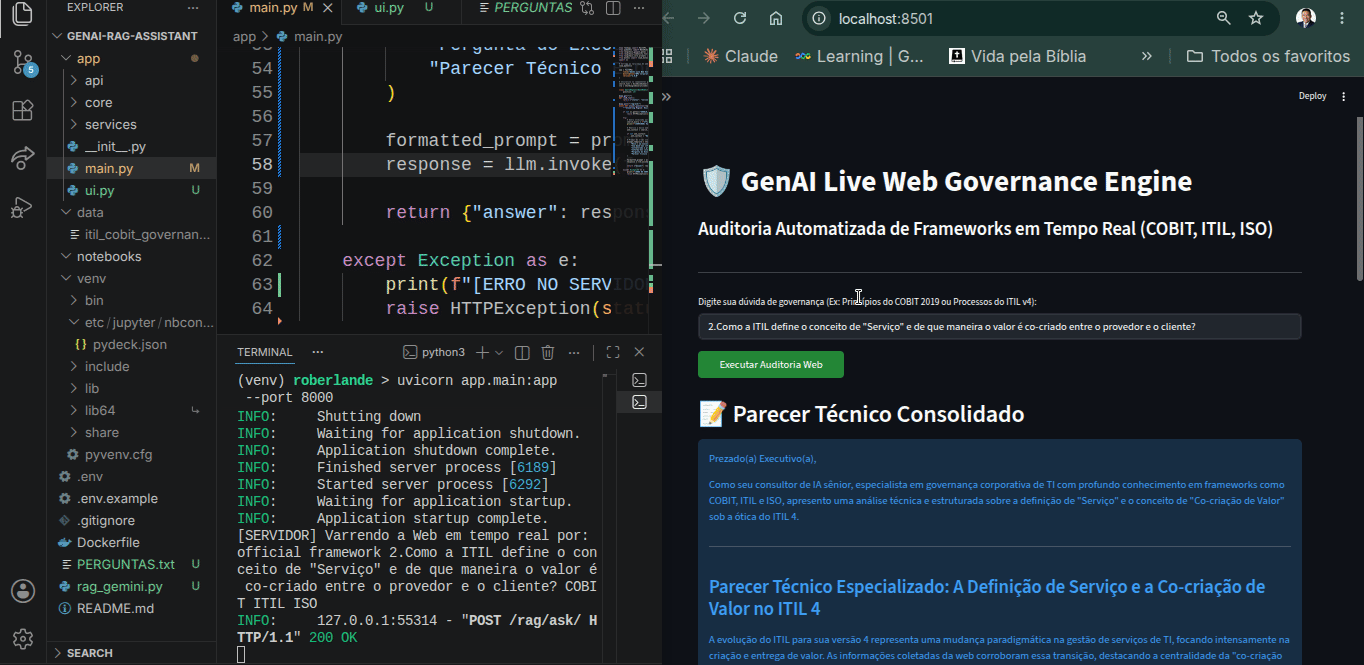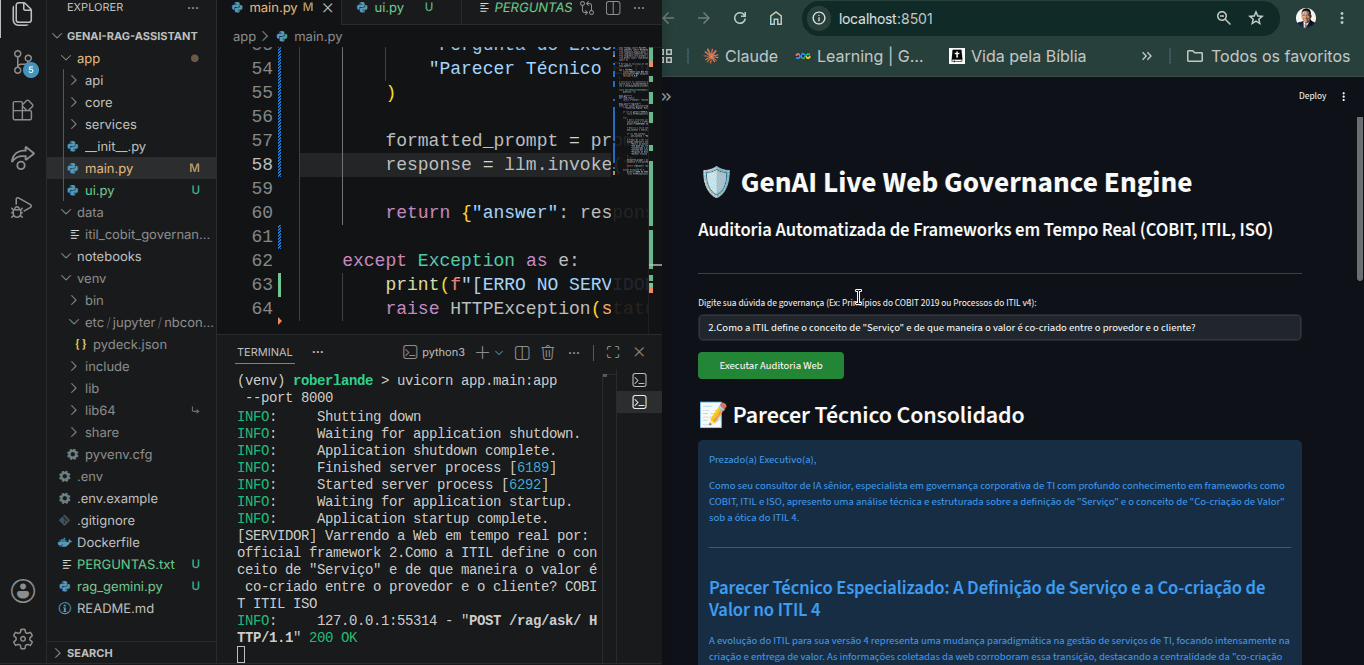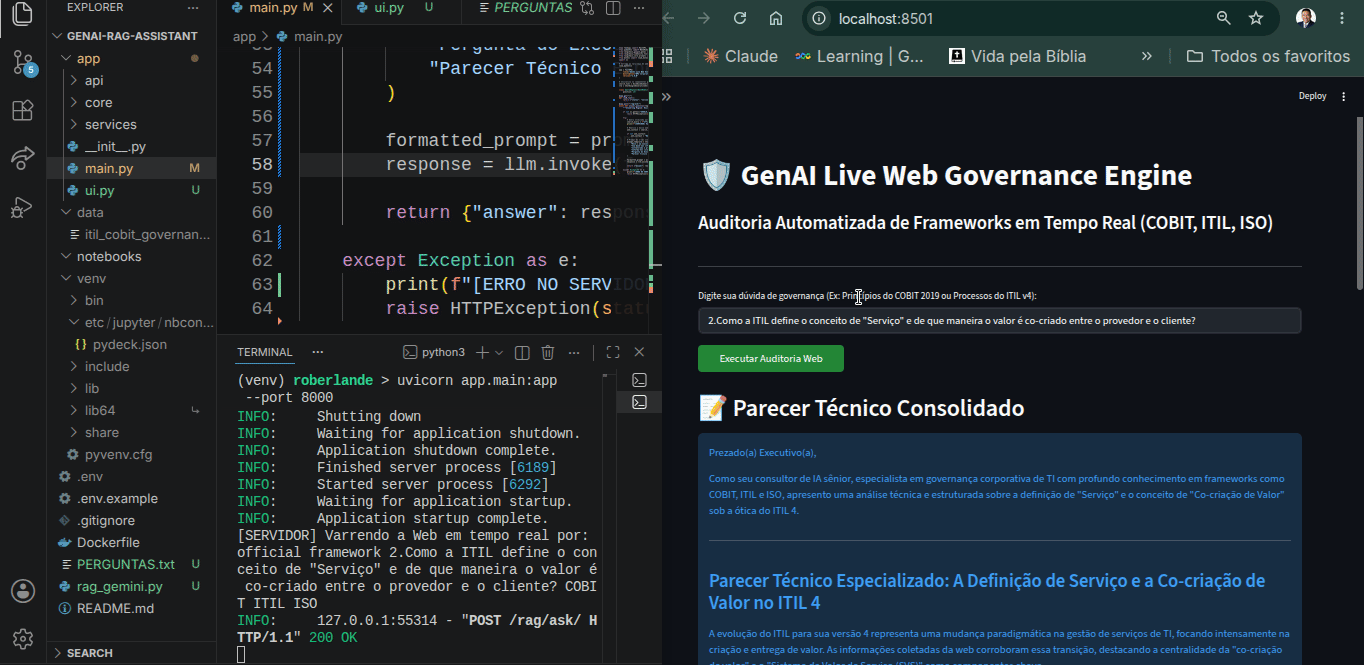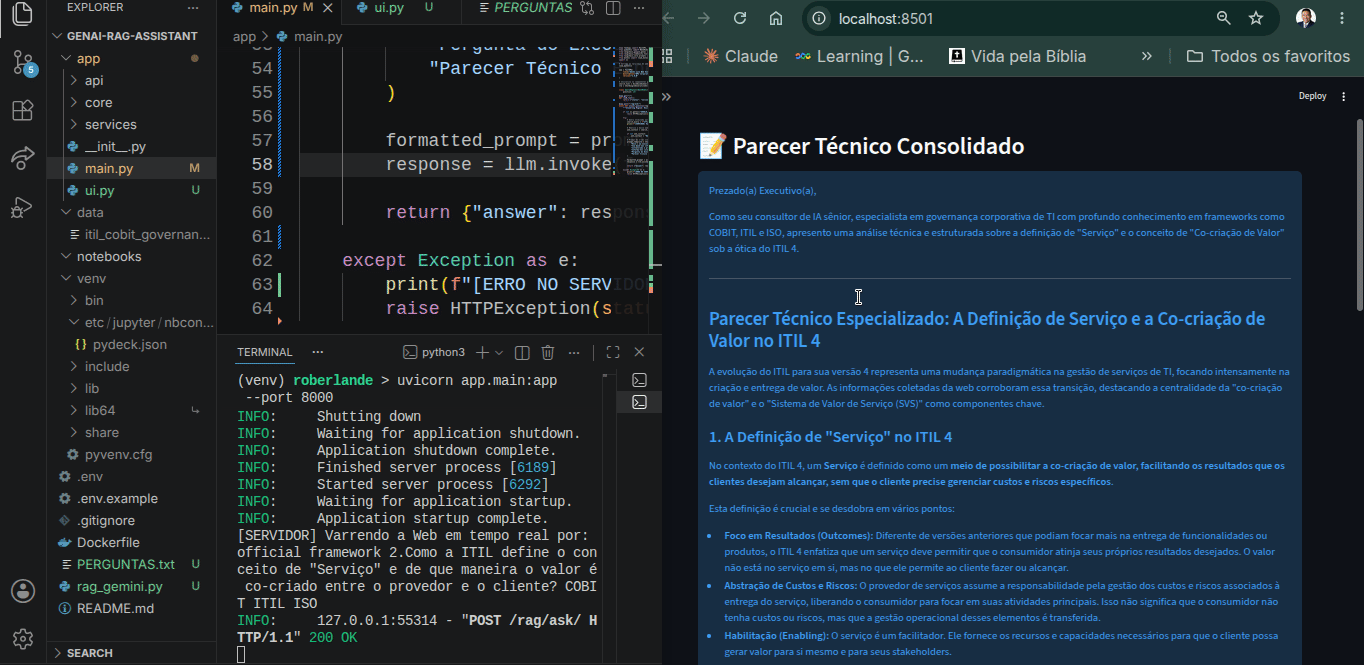
Recentemente, desenvolvi o **GenAI Live Web Governance Engine**, um assistente avançado de RAG (Retrieval-Augmented Generation) focado em auditoria e governança corporativa de TI (alinhando frameworks como COBIT 2019, ITIL v4 e ISO).
Neste artigo, compartilho a arquitetura desse ecossistema e os bastidores de uma verdadeira "caça aos bugs" de APIs que todo desenvolvedor moderno precisa conhecer.
## 🛠️ A Arquitetura do Sistema (O Ecossistema)
O projeto foi desenhado seguindo padrões de engenharia de software de nível de produção, dividindo-se em duas camadas principais:
1. **O Motor Backend (FastAPI - Porta 8000):** Responsável por carregar a base de conhecimento local no banco de dados vetorial **FAISS**, realizar buscas em tempo real na Web usando o ecossistema de ferramentas do **LangChain** e gerenciar a orquestração do LLM de forma assíncrona.
2. **A Interface de Usuário (Streamlit - Porta 8501):** Um front-end dinâmico e responsivo que permite ao usuário submeter pareceres técnicos e visualizar relatórios consolidados em Markdown gerados pela IA.
## 🔍 O Desafio Técnico: A Evolução dos Modelos na Prática
Durante os testes de integração do MVP, nos deparamos com o temido **Status 500 (Internal Server Error)**. Investigando os logs do servidor, identificamos um comportamento clássico em engenharia de IA: códigos que apontavam para modelos depreciados ou rotas antigas (gemini-1.5-flash ou formatos legados de embeddings).
A resolução exigiu uma refatoração cirúrgica em três frentes:
* **Alinhamento de Embeddings:** Atualizamos o pipeline de vetorização no FAISS para utilizar o modelo oficial mais recente, o gemini-embedding-2.
* **Atualização do Cérebro (LLM):** Substituímos as chamadas legadas do LangChain no main.py para invocar explicitamente o novíssimo **gemini-2.5-flash**, garantindo maior velocidade e menor taxa de alucinação.
* **Ajuste de Tipagem no Dicionário de Resposta:** Corrigimos o mapeamento de payload entre a interface e o motor. Onde o backend entregava a chave {"answer": ...}, o front-end buscava por "response", o que gerava a famosa mensagem "Nenhuma resposta gerada". Alinhando as chaves para "answer", a mágica aconteceu!
## 📊 O Resultado Final
O sistema agora está operando em alta performance! Ele consegue:
1. Receber uma pergunta complexa de governança (ex: *As Quatro Dimensões do ITIL v4 applied to Cloud*).
2. Varrer a internet em tempo real trazendo as discussões mais recentes.
3. Cruzar com a documentação local no FAISS.
4. Entregar um parecer técnico consolidado, extremamente estruturado, com saudações executivas e formatações impecáveis.
Tudo isso salvo, versionado e sincronizado com segurança via Git diretamente no meu repositório do GitHub!
## 💡 Principais Lições Aprendidas
* **Monitoramento de Logs é tudo:** O terminal do Uvicorn nos deu a pista exata (NOT_FOUND para o modelo antigo). Saber ler logs economiza horas de adivinhação.
* **IA muda rápido:** Manter-se atualizado com as nomenclaturas de modelos da Google (como a transição para a linha 2.5) é obrigatório para quem quer criar soluções resilientes.
Confira o código completo e a estrutura do repositório no meu GitHub:
👉 https://github.com/Roberlanderrsilva/genai-rag-assistant
Agradeço a todos que acompanham minha jornada de evolução em IA e Engenharia de Dados. Vamos para os próximos deploys! 🚀
#ArtificialIntelligence #GenerativeAI #FastAPI #Streamlit #LangChain #RAG #Python #Developer #DIO #Github
