
CRIAÇÃO, LLM E RAG – A INTELIGÊNCIA ARTIFICIAL, ATUAL E LÚCIDA
- #IA Generativa
Este é um artigo minimalista, porém, relevante para a construção do entendimento sobre alguns aspectos que compõem a Inteligência Artificial. Sua única intenção é simplificar o início do aprendizado ao diminuir a carga de termos técnicos em uma apresentação mais suave, mas sem perdê-los de vista.
Apesar de ser impossível esgotar todo o assunto, é clara a necessidade de aprofundamento por meio de cursos específicos e estes podem ser, inclusive, encontrados aqui na DIO.
I - Uma breve e resumida explicação sobre IA Generativa
Ao recorrer a uma definição formal, Tom Taulli (2024, p. 22), nos traz que: "A IA generativa é um ramo da Inteligência Artificial (IA) que permite a criação de conteúdo novo e único." Analisando o significado da palavra ‘Generativa’, fica evidenciado que se trata de algo que gera, que cria.
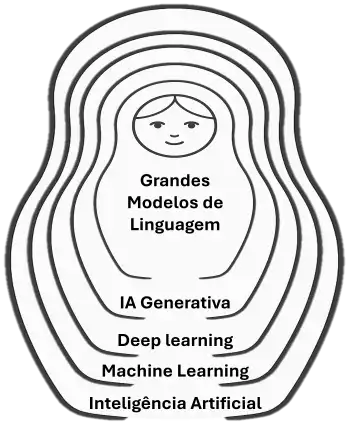
A IA generativa está concentrada em um subconjunto dentro do Deep Learning (Aprendizado Profundo) que por sua vez é outro subconjunto dentro do Learning Machine (Aprendizado de Máquina) sendo este o subconjunto mais amplo, dentro do conjunto que a Inteligência Artificial representa.
Voltando à camada da IA generativa, dentro dela há o subconjunto que representa os modelos de linguagem, os LLMs.
Fonte: Diagrama elaborado pelo autor com base em imagem gerada pelo Copilot (Microsoft).
É importante deixar claro que a IA Generativa não está limitada somente aos LLMs, mas também aos modelos que são capazes de gerar criações visuais (imagem) auditivas (áudio, músicas) e audiovisuais (vídeos).
II - LLM – Large Language Model
Basta mencionar Inteligência Artificial e o termo LLM – Modelo de Linguagem de Grande Escala – é o que mais aparece. Os modelos são sistemas de IA treinados com enormes quantidades de texto, originalmente fornecidos por humanos, mas que evoluíram para textos também produzidos pela própria IA.
Os modelos de linguagem são responsáveis pelas respostas que recebemos, por exemplo, dos chatbots ou dos assistentes de IA como o Gemini, o ChatGPT, o Perplexity, entre outros. São construídos por meio de um aprendizado profundo, o Deep Learning, que tem como base a arquitetura Transformer.
Desmistificando a crença que muitas pessoas ainda têm sobre a Inteligência Artificial, os modelos LLM não entendem ou pensam como os seres humanos. Ele são orientados pela estatística preditiva que busca prever qual será, a partir da primeira, a próxima palavra, e seguirá essa sequência até o final.
As palavras recebem a denominação de token, mas não isso não as torna exclusivas desse termo. Também podem ser considerados tokens de entrada e saída mais comuns, partes de palavras, pontuação e caracteres especiais.
É imprescindível que a estatística preditiva não seja confundida com adivinhação, porque se não houver coerência e coesão nos dados fornecidos na entrada, denominados como tokens, as saídas poderão não ser exatamente o que se espera e inclusive contribuir para o que é chamado de “Alucinação”.
Retornando à arquitetura Transformer, o seu principal componente, a Atenção Própria, ou como no original, Self-Attention, consiste no mecanismo de aprendizado do contexto. Quando recebe diferentes tokens, consegue criar relações contextuais entre as palavras, mesmo que estejam distantes entre si.
O treinamento dos LLMs é dividido em duas etapas. Diferente do Self-Attention, que é um componente da arquitetura Transformer, o pré-treinamento e o treinamento são os processos que a utilizam para o aprendizado de máquina.
O pré-treinamento é a fase na qual o modelo recebe um imenso volume de informações variadas, que vão desde a gramática e os padrões linguísticos de cada região até fatos gerais. Pode ser considerada uma etapa estática, porque já existem diversos elementos de entrada.
Involuntariamente, a dinâmica do pré-treinamento provoca a data de corte que em uma explicação bastante resumida, significa uma falha provocada pela impossibilidade de acessar eventos, dados e documentos recentes de forma ampla, criando gaps (intervalos) de informação.
A fase seguinte, o treinamento em si, é o momento do ajuste fino, processo realizado pelos engenheiros como um treinamento formal para que o modelo seja refinado antes de ser lançado. O termo técnico é Fine-Tuning/RLHF, que significa em português Reforço por Feedback Humano.
Apesar de mencionados nessa seção, a Engenharia de Prompt, a Data de Corte e a Alucinação serão tratados a seguir, com maior aprofundamento e exemplos didáticos, de fácil entendimento uma vez que representam experiências reais.
III - A métrica do prompt não é a beleza, mas sim a clareza
A Engenharia de Prompt é a arte de saber escrever para que o seu interlocutor possa compreender e da mesma forma que entre os humanos existe a engenharia social, que pode ser para o bem ou para o mal, fazer o que desejamos, nos trazer o resultado esperado.
A construção correta, adequada ao contexto e a quem a estamos direcionado, é o núcleo da Engenharia de Prompt enquanto o chat é o espaço no qual é informado para o modelo de Inteligência Artificial quais são os objetivos e os resultados desejados.
É importante que as informações tenham sentido, porque a Inteligência Artificial generativa não adivinha o contexto e a intenção do que está recebendo pelo prompt caso existam palavras rebuscadas, frases difíceis ou soltas, sem coesão e que não estejam interligadas. Isso prejudica o entendimento.
Atualmente, a IA não processa as solicitações no prompt somente em inglês. As empresas ajustaram o aprendizado de máquina e o treinamento com um enorme volume de textos em diversos idiomas. Ainda assim, esse fato não isenta o usuário de seguir algumas boas práticas.
Prompts eficazes e eficientes podem ser construídos criando personas. Por exemplo, ao buscarmos informações relacionadas à reforma de uma casa, orientamos o modelo de IA que a partir daquele momento ele deve assumir a personalidade do maior empreiteiro do país, com décadas de experiência no ramo.
Reforços para refinar o conteúdo da interação e possibilitar à IA entender o raciocínio em desenvolvimento:
- Dividir tarefas complexas em várias conversas (prompts) menores;
- Fornecer exemplos;
- Realizar analogias;
- Utilizar termos técnicos que não variam tanto em inglês quanto em português.
O diferencial, realmente, está no modo como a informação é passada e quanto ao mito das frases reduzidas, dos prompts curtos, há pelo menos um aspecto que demonstra a eficiência em escrever chats mais longos e bem detalhados e que será mencionado a seguir.
Todas as ações e boas práticas mostradas até agora podem ser perdidas caso a escrita ou o áudio não considerem pontos essenciais. Exceto os termos técnicos que não podem nem devem ser traduzidos do inglês, as palavras em português precisam ser avaliadas em conformidade com suas particularidades.
Alguns procedimentos excelentes durante a construção de um prompt são:
- Evitar termos e palavras difíceis e rebuscadas;
- Evitar sinônimos que possibilitem interpretações diferentes e que atrapalhem o entendimento;
- Priorizar frases bem construídas com linguagem clara, simples e direta.
Inclusive, a possibilidade de redundância e do uso de palavras repetidas nessa etapa pode ser considerada, porque existe uma grande quantidade de evidências sobre a sua eficiência. Escrever as mesmas palavras e as mesmas frases de forma diferente, também.

Fonte: Captura de tela da conversa do autor com o assistente de IA Gemini (Google).
Portanto, não é necessário utilizar palavras mais difíceis e frases de impacto, porque a Inteligência Artificial não está avaliando o texto. Ela precisa e ‘quer’, apenas, entender o que é para ser feito, o que está sendo buscado.
IV – RAG, informações atuais e manutenção da sanidade artificial
A seção sobre os LLMs citou o conhecimento limitado e a data de corte. Para uma melhor compreensão será necessário retornar ao ano de 2022, quando a OpenAI lançou o ChatGPT. Esse período pode ser considerado como o início da popularização da Inteligência Artificial.
Porém, em pouco tempo, notou-se que as informações fornecidas por esse modelo faziam referência somente até setembro de 2021. Essa foi a origem da primeira data de corte. No começo de 2023, o Google apresentou um modelo de IA vinculado ao seu buscador que permitia trazer conteúdo mais atualizado.
Consequentemente, como organizações sempre estão prestando atenção ao que os seus concorrentes estão criando com sucesso, a OpenAI buscou corrigir a sua falha e as melhorias foram escalando sendo seguidas também pelas outras empresas.
Foi nesse contexto que surgiu a RAG – Retrieval-Augmented Generation ou Geração Aumentada por Recuperação. Sua principal vantagem é a obtenção das informações em tempo real e o acesso ao conteúdo bruto das fontes responsáveis pelos dados atualizados por meio dos links apresentados com os resultados.
A escolha por esse padrão foi tão assertiva que trouxe na sua esteira a principal estratégia para reduzir as alucinações que são uma espécie de sobrecarga que os modelos apresentam, eventualmente. Nesse cenário, uma vantagem fez com que surgisse uma solução muito bem-vinda, mesmo que parcial.
As alucinações acontecem quando os modelos fornecem informações que em um primeiro momento parecem corretas, uma vez que o modelo utiliza a sua função preditiva sobre os tokens mais prováveis sem priorizar o mais verdadeiro, ou seja, o que traz o significado mais próximo do que foi solicitado.
A prioridade equivocada é resultado da incoerência estatística do texto sem observar o fato e é nesse ponto que a RAG oferece uma solução, porque traz fatos atualizados e isso reduz a confusão que a carência de informação costuma provocar. Enfim, a alucinação é, praticamente, o “Burnout das Ias”.
A arquitetura da RAG segue um fluxo em duas etapas. A fase da Indexação é a primeira, quando acontece a preparação e as bases de conhecimento são armazenadas em bancos de dados vetoriais, diferentes dos bancos relacionais, uma vez que buscam os dados pelo contexto e não pela exata correspondência.
A segunda etapa é dividida entre Recuperação e Geração. A Recuperação ocorre durante a interação entre o usuário que faz uma solicitação e o modelo de IA que faz a conversão do que lhe foi pedido. A busca pelos dados que possuem contexto semelhante dentro do banco de dados vetorial é realizada.
Antes da Geração, há um intervalo para que as informações relevante que encontradas sejam anexadas à pergunta e ocorre a criação de um vínculo que aumenta o conteúdo. Por fim, o modelo fará a leitura do conteúdo gerado que considerou apenas as informações relevantes e o devolverá para o usuário.
Informações e buscas baseadas no contexto e não na exatidão dos dados reduzem a tentativa de os modelos adivinharem as respostas e fornecerem conteúdo sem nexo, com erro e sem qualquer relevância, tornando, inclusive, a experiência do uso da IA desagradável.
V – A diminuição e o controle das alucinações com o auxílio da RAG
Uma das maiores soluções RAG da atualidade é o aplicativo que se tornou bastante conhecido e utilizado: o NotebookLM do Google. A sua dinâmica é exatamente focar no contexto do material que é fornecido, isolando-se das fontes exteriores para retornar o resultado que o usuário deseja.
Para fins didáticos: o NotebookLM funciona como um equipamento desconectado de qualquer rede, limitado apenas ao conteúdo que está à disposição em suas unidades de armazenamento. O usuário, por sua vez, ciente dessa limitação, não fará requisições que sabe que não serão atendidas.
A analogia que foi mostrada utilizando o Notebook LM e um dispositivo isolado de fontes externas ajuda a entender como as alucinações foram reduzidas. Trata-se de um universo fechado e o sistema não teria condições de fornecer as saídas que estivessem além de suas capacidades.
Então, para consolidar o entendimento, quando fazemos o upload de diversos tipos de arquivos para o NotebookLM, todas as informações retornadas são retiradas dessas fontes que nós mesmos fornecemos. Nada é buscado na Internet e, consequentemente, em fontes externas. Sem palpites, sem alucinações.
Pergunta: se o NotebookLM traz dados atuais e assertivos baseados nas fontes que fornecemos, por que também é garantido que o retorno recebido de modelos convencionais como o Gemini, o ChatGPT e o DeepSeek, por exemplo, é verdadeiro e está atualizado? A resposta: porque existe a RAG.
Um bom exemplo é como o padrão funciona no Gemini. Uma consulta como “Qual o nome do jogador que fez o gol da classificação para a final da Libertadores da América agora há pouco?”, é feita no prompt. Ele não vai saber responder. Não está no seu aprendizado. Então, o modelo recorre ao Google Search.
Por coincidência o Gemini é do Google, mas os outros modelos também utilizam buscadores em parceria ou próprios, que utilizam crawlers varrendo a Internet atrás de informações para indexar. O Google Search encontra a informação em um site e o Gemini a retorna junto com o link de onde foi encontrada.
Como foi visto nessa sequência, a ação para contornar os dois problemas foi bem-sucedida. Ainda que não seja a solução final, a obtenção de informações atuais evitaram alucinações e que dados que não são os corretos e que podem causar prejuízos de diversas naturezas fossem recuperados.
As melhorias proporcionadas pela RAG podem, sim, consolidar o padrão como a melhor solução encontrada, até agora, para resolver o problema da data de corte e das alucinações.
VI – Conclusão
Possuímos maravilhosas ferramentas na ponta dos nossos dedos ou ativadas pelas nossas próprias palavras, utilizando microfones e outros tipos de entrada de dados em um prompt.
A referência que fazemos ao Gemini, ao ChatGPT, ao Perplexity e aos outros assistentes, simplesmente como Inteligência Artificial, conforme o nosso aprofundamento e aprendizado é alterada e passamos a entendê-los como Modelos de Inteligência Artificial, que é exatamente o que eles são.
Também foi esclarecido que quanto mais informações com riquezas de detalhes, mesmo que redundantes e repetidas, são válidas para obtermos os resultados esperados e, aliados à RAG, a forma mais eficiente para evitar as alucinações.
O que não pode haver é ambiguidade, a inserção de palavras que possuem diversos sentidos e que não estejam corretamente contextualizadas. Dessa forma, os modelos conseguem encontrar as melhores respostas e evitar as alucinações.
E por fim, o padrão que pode ser considerado como a estrela que contornou a grande problemática da defasagem, a RAG. Afinal, a limitação temporal para a aquisição dos dados, das informações e do conhecimento só contribuem para a formação da sabedoria incompleta e das tomadas de decisões atrasadas.
Go Ahead!
Referências
TAULLI, Tom. Programação Utilizando IA. 2. ed. São Paulo: Novatec Editora Ltda, 2024.




