

Como reduzir alucinações em LLMs usando RAG: uma aplicação prática em ETL com IA Generativa
- #Data
- #Python
- #LLMs
1. Introdução
Com a crescente adoção de Large Language Models (LLMs) em aplicações reais, surge um desafio recorrente: como garantir que as respostas geradas sejam precisas, confiáveis e contextualizadas?
Para explorar essa questão de forma prática, este artigo utiliza como estudo de caso um dos desafios técnicos disponibilizados pela DIO, intitulado “Pipeline ETL com IA Generativa”.
O desafio propõe a criação de mensagens personalizadas para clientes, indo além do marketing genérico. A ideia é utilizar o poder da Inteligência Artificial para entender o perfil de cada cliente e gerar comunicações financeiras relevantes, aumentando o engajamento e a assertividade da comunicação bancária.
Em soluções mais comuns, a abordagem geralmente se limita à criação de um agente bem instruído por meio de um prompt cuidadosamente elaborado. Essa estratégia funciona até certo ponto.
No entanto, surge uma pergunta fundamental: e se fosse possível gerar mensagens verdadeiramente personalizadas para cada perfil de investidor, com base em conhecimento confiável e estruturado?
Para entregar uma solução mais robusta, escalável e confiável, a técnica de Retrieval-Augmented Generation (RAG) se mostra uma alternativa poderosa.
2. O que é RAG?
Retrieval-Augmented Generation (RAG) é uma técnica que otimiza a saída de uma LLM ao permitir que o modelo consulte dados externos durante o processo de geração de respostas, sem a necessidade de retreinamento.
Essa abordagem foi apresentada no artigo “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, publicado em 22 de maio de 2020, como uma solução para um problema comum em modelos de linguagem: as alucinações, quando o modelo gera informações incorretas ou não fundamentadas.
Além de mitigar esse problema, o RAG resolve outra limitação importante: o acesso a informações específicas ou atualizadas, evitando processos caros e demorados de retreinamento.
Com isso, a LLM passa a recuperar informações de fontes confiáveis e previamente definidas, oferecendo maior controle sobre o conteúdo gerado e tornando o processo mais transparente para usuários e organizações.
3. Como implementar um RAG?
3.1. Preparação da Base de Conhecimento (Ingestão)
A primeira etapa consiste em transformar documentos brutos em um formato consultável pela IA. Esse processo envolve:
- Carregamento: uso de bibliotecas como LlamaIndex para extrair dados de PDFs, bases SQL ou APIs;
- Fragmentação (Chunking): divisão dos textos em blocos menores e semanticamente coerentes;
- Embeddings: conversão desses fragmentos em vetores numéricos utilizando modelos de embedding, como OpenAI ou HuggingFace;
- Banco de Dados Vetorial: armazenamento dos vetores em soluções como Pinecone, Milvus ou Weaviate.
Para aplicações locais ou de menor complexidade, ferramentas como FAISS ou ChromaDB são boas opções.
Outra alternativa bastante interessante é o pgvector, uma extensão do PostgreSQL que permite busca vetorial, ideal para quem já trabalha com SQL e deseja integrar RAG ao ecossistema relacional.
3.2. Fluxo de Recuperação (Retrieval)
Quando o usuário realiza uma pergunta, o sistema executa os seguintes passos:
- Converte a pergunta em um embedding;
- Utiliza esse embedding para realizar uma busca por similaridade no banco vetorial;
- Recupera os chunks de texto mais semanticamente próximos;
- Retorna os N trechos mais relevantes para serem usados como contexto.
A similaridade é geralmente calculada por meio da similaridade do cosseno, uma métrica que mede o quão próximos dois textos são em significado, mesmo quando utilizam palavras diferentes.
3.3. Geração da Resposta (Generation)
Na etapa final, ocorre a geração da resposta propriamente dita:
- Prompt Dinâmico: criação de um template que instrui a LLM a responder exclusivamente com base nos dados recuperados;
- Geração Grounded: o modelo (como GPT-4o ou Claude 3.5) processa o contexto fornecido e gera uma resposta fundamentada, reduzindo alucinações e aumentando a confiabilidade.
Para quem deseja compreender melhor a aplicação prática em código, recomendo o seguinte vídeo do canal Inteligência Mil Grau:
https://www.youtube.com/watch?v=qTpy8Rx02-A
4. Como o RAG ajuda no desafio proposto?
Para demonstrar a aplicação prática do RAG, foram utilizados registros fictícios de clientes presentes na base de dados, cada um com um perfil de investidor distinto.
A partir desses dados, as LLMs foram capazes de gerar mensagens personalizadas, alinhadas ao perfil individual de cada cliente. Investidores conservadores receberam recomendações voltadas à segurança e previsibilidade, enquanto perfis moderados e arrojados receberam sugestões compatíveis com seus objetivos e tolerância a risco.
Esse resultado foi possível porque a LLM não gerou respostas apenas com base em seu conhecimento interno.
Nesse contexto, foi criado um documento fictício, simulando opções de investimentos disponíveis no Santander. Esse material foi utilizado como base de conhecimento do RAG.
Em um cenário real, o ideal seria trabalhar com um catálogo robusto de produtos financeiros, aliado a regras de negócio e validações mais profundas, garantindo ainda mais precisão e confiabilidade nas respostas geradas.
4.1. Amostra da Base de Dados de Clientes
A seguir, uma amostra simplificada da base de clientes utilizada no experimento. Cada registro contém informações básicas e o perfil de investidor, que será utilizado pelo RAG para contextualizar a geração das mensagens.
[
{
"id": 10,
"nome": "Helena Martins",
"conta": "00101234-5",
"perfil_investidor": "Moderado"
},
{
"id": 11,
"nome": "Igor Guimarães",
"conta": "00112345-6",
"perfil_investidor": "Arrojado"
},
{
"id": 12,
"nome": "Juliana Paiva",
"conta": "00123456-7",
"perfil_investidor": "Conservador"
}
]
4.2. Exemplos de Mensagens Geradas com RAG
A seguir, exemplos das mensagens geradas pela LLM após o processo de recuperação + geração, considerando o perfil de cada cliente.
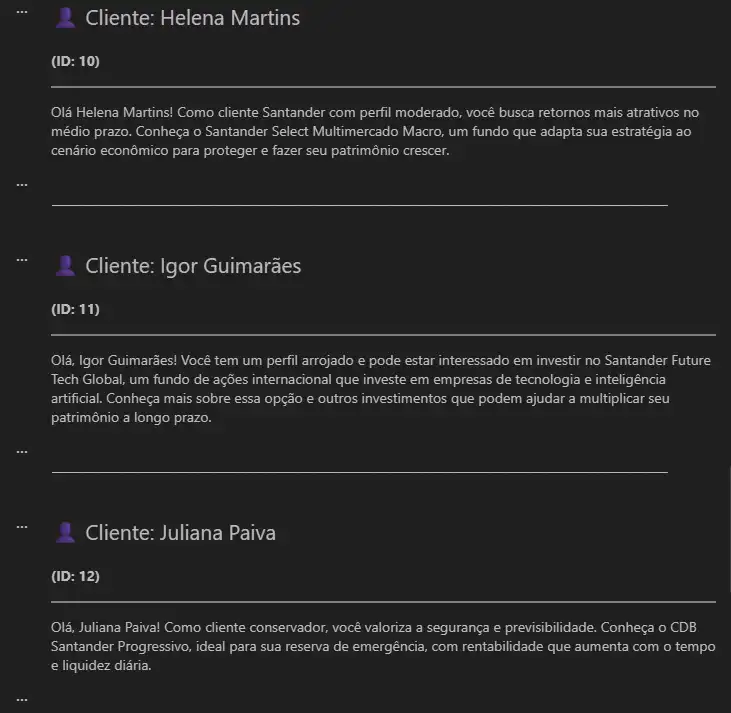
4.3. Análise dos Resultados
Observa-se que cada cliente recebeu recomendações coerentes com seu perfil de investidor, utilizando informações provenientes da base de conhecimento externa.
Isso demonstra como o RAG permite que a LLM gere mensagens personalizadas, contextualizadas e embasadas, reduzindo alucinações e aumentando a confiabilidade da comunicação.
Sem o RAG, a LLM poderia sugerir produtos inadequados ou inexistentes.
Com o RAG, a IA consulta antes de responder.
O código completo da solução pode ser encontrado no repositório:
https://github.com/luccasena/Santander-ETL-com-Python/blob/main/main.ipynb
5. Conclusão
O uso de Retrieval-Augmented Generation (RAG) é uma estratégia fundamental para tornar aplicações baseadas em LLMs mais seguras, confiáveis e alinhadas aos objetivos do negócio.
No contexto do desafio do bootcamp, essa técnica possibilita a criação de comunicações bancárias altamente personalizadas, reduzindo erros, evitando alucinações e aumentando significativamente o engajamento dos clientes.
Mais do que gerar texto, o RAG transforma a Inteligência Artificial em uma ferramenta de tomada de decisão orientada por dados, algo essencial para aplicações reais de mercado.
Referências
- AWS – What is Retrieval-Augmented Generation (RAG)
- https://aws.amazon.com/pt/what-is/retrieval-augmented-generation/
- IBM – O que é similaridade de cosseno?
- https://www.ibm.com/br-pt/think/topics/cosine-similarity
