

Boas Práticas de criação de soluções da nuvem AWS:
- #AWS
Boas Práticas de criação de soluções da nuvem AWS:
Quando se executa como workloads na nuvem AWS, pode dimensionar a infraestrutura e de forma rápida e produtiva. Uma implementação de escalabilidade em todas as camadas da infraestrutura é uma das práticas recomendadas.
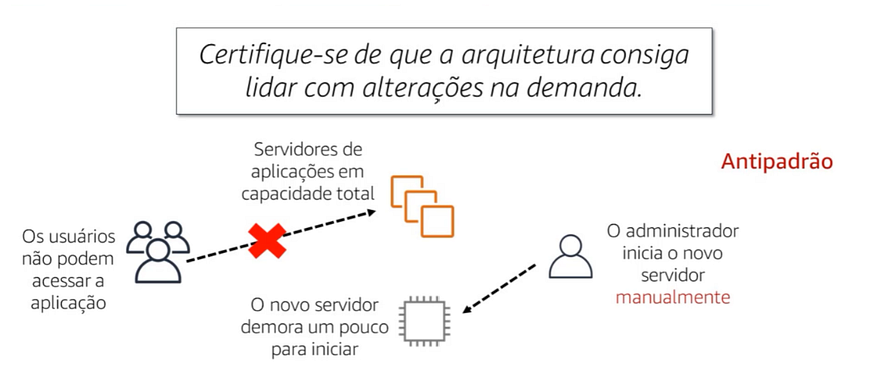
Para compreender a importância da escalabilidade, considere este anti padrão, na qual é realizado de forma reativa e manual. Neste cenário, quando os servidores da alocação não atingem a capacidade total, os usuários podem acessar-la. Os administradores executam manualmente uma ou outra vez para usar uma ou mais instancias para administrar alguns minutos disponíveis para uso aninhado que uma carga, caso mais instancia para iniciar.
Esse tipo de estratégia reduz a disponibilidade da aplicação.

Com a escalabilidade, você melhora o design para antecipar a necessidade de mais capacidade e entregá-la antes que seja tarde demais.
Por exemplo, você pode usar uma solução de monitoramento, como o Amazon CloudWatch, para adicionar uma escalabilidade de recursos com base em um limite especificado, como o uso da CPU maior que 60% por cinco. No Amazon CloudWatch, também é possível criar medições medidas.
Quando um alarme é acionado, o Amazon EC2 Auto Scaling inicia imediatamente uma nova instância. Essa instância estará pronta para a capacidade alcançada, o que manterá a disponibilidade.
O design do sistema deve também ser escalável. Quando a demanda cair, você poderá liberar o recurso que não é mais necessário para reduzir o custo e a complexidade.
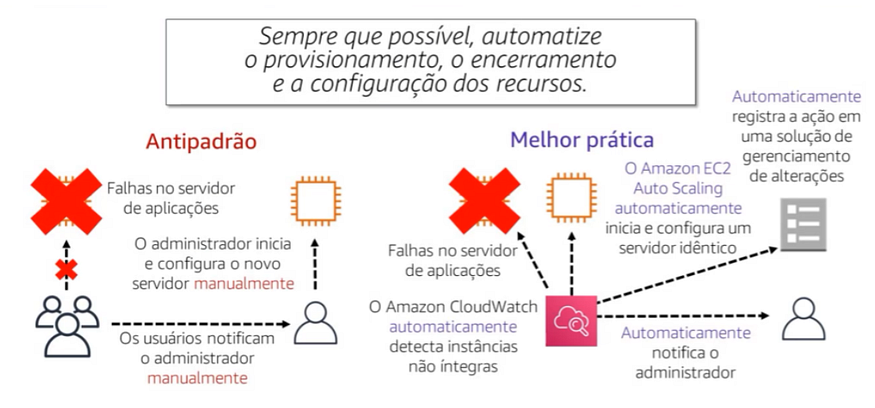
A prática recomendada a seguir é a automatização do ambiente. A AWS recursos ferramentas integradas de monitoramento e automação em cada camada da infraestrutura, com o uso dessas ferramentas, sua infraestrutura pode responder rapidamente como, você pode usar ferramentas como Cloudarch e Amazon EC2 Auto Scaling para detectar recursos não integrados e automatizar a execução de de substituição, também é possível programar notificações em caso de alterações nas alocações de recursos.

Outra prática recomendada é considerada seus recursos descartáveis, antes da virtualização e da computação na nuvem, incluir um novo adicionar um novo recurso físico, com este modelo, é fácil comprar componentes mais específicos dos quais você precisa para se preparar para o uso. A regra para uso durante picos é cara inflexível.
No ambiente de nuvem, você pode usar serviços em vez de ativos de recursos físicos, neste modelo você pode facilmente considerar seus recursos descartáveis, excluir e reconfigurar seus recursos.
A migração entre instâncias ou outros recursos é bastante simples. Você pode responder rapidamente às mudanças nas necessidades de capacidade, fazer upgrade das aplicações e gerenciar o software subjacente.
Mais uma prática recomendada é usar componentes com baixo. Como infraestruturas tradicionais são em cadeias de servidores avançados integrados, cada um com uma finalidade específica.
O problema é que uma interrupção no sistema pode ser grave, quando há falha em um componente ou uma camada. Isso também impede uma escalabilidade.
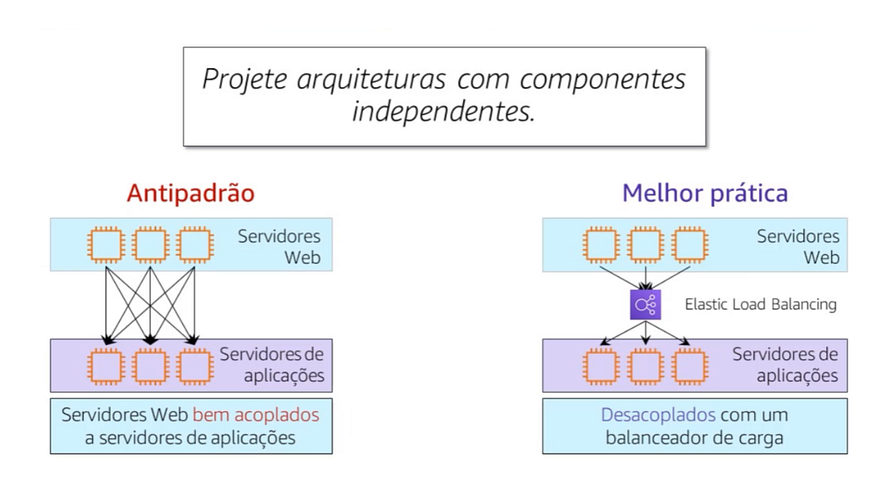
Ao adicionar ou remover servidores de uma camada, você também deve conectar todos os servidores de cada camada de conexão. Com baixo integrado, você usa soluções gerenciadas como intermediarias, balanceadores de carga e filas de mensagens, entre como camadas do sistema. Com esse design, as intermediarias resolvem automaticamente como falhas e processam a escalabilidade de componentes ou camadas.
Observe o exemplo à direita que demostra um balanceador de carga que roteia encaminhamentos entre os servidores WEB e os servidores de aplicações, se um servidor de aplicações ficar inoperante o balanceador de carga automaticamente começou a todo o tráfego para os dois servidores íntegros.

Outra prática recomendada é projetar serviços, não servidores. Por que vamos analisar o EC2 e não deve ser implementado uma solução única para projetar uma solução flexível, o contêiner ou soluções podem ser mais apropriados. E importante sempre considerar que é mais adequado às suas necessidades.
Com as soluções sem servidor e os serviços gerenciados da AWS, você não precisa provisionar configurar e gerenciar suas instâncias do EC2.
As soluções gerenciadas podem substituir como soluções, alguns serviços em gerenciamento de serviços Amazon com custo menor exemplos: AWS Lamb DynamoDB DynamoDB, Ela Simples Email e Amazon.

Outras práticas recomendadas entenda os requisitos da carga de trabalho e selecione uma solução de banco de dados desses requisitos. Nos datacenters tradicionais e ambientes on-premises, como as licenças de hardware disponíveis e disponíveis podem ser armazenadas como opções de soluções de dados disponíveis. E recomendada a escolha de um datastore com base nas necessidades dos ambientes das aplicações.
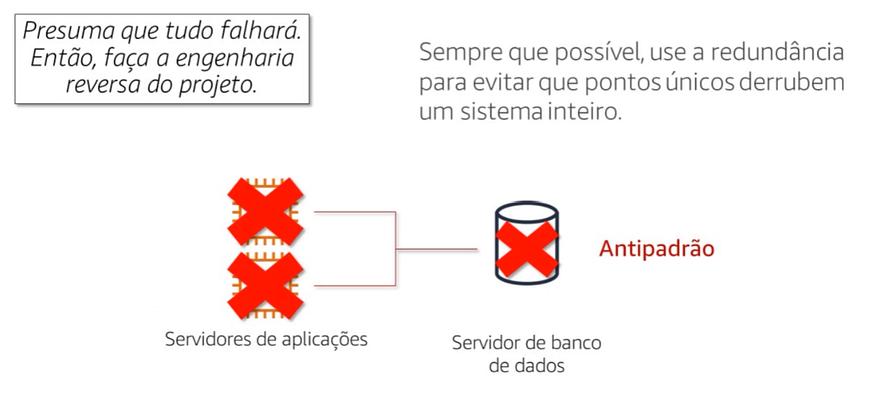
Sempre elimine possíveis pontos únicos de falha da arquitetura.
Dois servidores de sistema de conexão conectando um único servidor de dados acima de um único servidor de dados, o servidor de dados que opera um único ponto de falha, quando ele fica com os servidores de falha, também deve ser usado em dois servidores de banco de dados.
Os servidores de aplicações físicas continuam funcionando mesmo o hardware subsequentes, para removidos ou substituídos.
Isso não significa que você precisa sem duplicar todos os componentes, que só iniciam de acordo com a atividade de serviço para momentos, você pode usar soluções de gerenciamento também da AWS quando necessário os componentes quando necessário pode ser usado um serviço gerenciado em que o hardware subjacente com falha e substituído automaticamente.
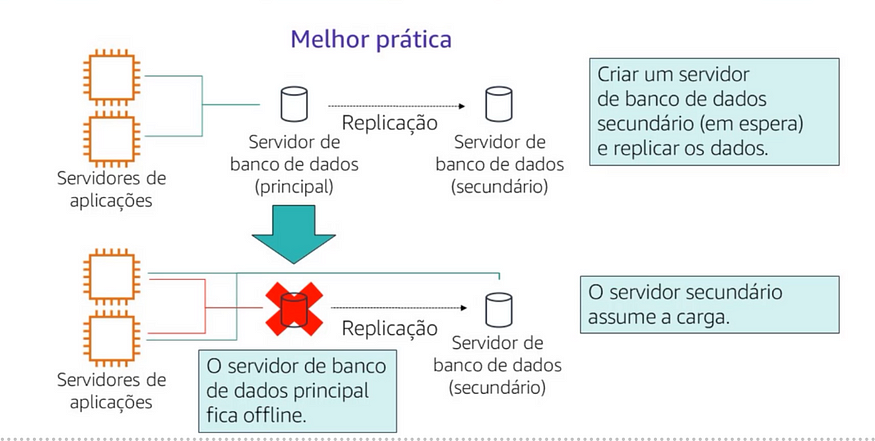
Para o ponto único de falha no exemplo que acabamos de examinar, é possível criar um servidor de banco de dados secundário ou em espera e replicar os dados.
Nenhum exemplo de banco de dados primários offline

A programação em permite trocar como despesas de capital por despesas financeiras, como despesas de capital são conhecidas como CapEx, elas se referem a fundos que uma empresa usa para adquirir, fazer upgrade e manter ativos físicos, como imóveis, edifícios industriais ou equipamentos, neste modelo você paga no datacenter, outros servidores ativos ou não, os serviços da AWS usam um modelo de custo de variável variável, isso quer dizer que você paga apenas pelos serviços individuais de que necessita, pelo tempo que você use, dentro de cada serviço você pode otimizar o custo. 2 serviços compatíveis com diferentes níveis de preços e configurações ou modelos, tenha em mente que a replicação de uma configuração de datacenter on-premises de servidores semana4h são executados na nuvem por 7 tem um custo alto.
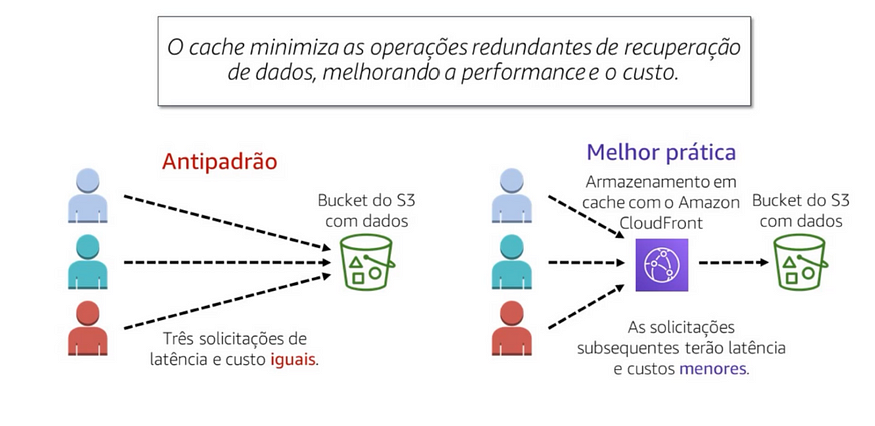
O armazenamento é uma técnica que torna as solicitações de dados em cache e uma mais rápida e reduz a taxa de transferência da transferência. Ele armazena os próximos dados de referência em local porque eles podem ser armazenados vez.
Nenhum exemplo anti padrão, serviço de armazenamento em cache e usado com o Amazon Simple Service ou Amazon S3, quando alguém solicita um arquivo de um backet do S3, cada solicitação leva o mesmo tempo para ser concluído. Além disso, cada solicitação tem o mesmo custo, no exemplo de infraestrutura prática recomendada, a usa o Amazon CloudFront para oferecer armazenamento em cache em frente ao S3, neste cenário, a pedido inicial procura o arquivo no CloudFront, se ele não for encontrado, o CloudFront solicita o arquivo do S3, em seguida, o CloudFront armazena uma cópia do arquivo em um ponto de presença próximo ao usuário e envia uma cópia para o usuário que fez a solicitação.
À medida que as solicitações subsequentes do arquivo encontram uma cópia no ponto de presença no Cloudfront , e não no S3, isso reduzirá a latência e o custo após a primeira solicitação você não precisara pagar pelo que foi enviado para fora do S3 enquanto ele ainda estava armazenado em cache não CloudFront .

A segurança não se trata apenas de passar pelo limite externo da infraestrutura, mas também envolve proteger os ambientes individuais e seus componentes protegidos dos outros.
Por exemplo, você pode criar grupos de segurança para as instâncias do EC2 que permitem especificar quais portas nas instâncias podem enviar e receber tráfego. Os grupos podem determinar a origem do tráfego, você também pode usar grupos de segurança para reduzir a probabilidade de uma ameaça de segurança instancia se espalhar para todas como outras instâncias no ambiente, também e tomar o destino em uma previsão com os outros serviços.
Instagram: bugs.dat
linkedln: Maria Isabelli Pinto
Github: MariaIsabelli


