

Amazon RDS: O Superpoder dos Bancos de Dados na Nuvem que Todo Dev Deveria Conhecer
- #AWS
- #Python
- #Banco de Dados
- #Banco de dados relacional
🎯 Introdução: Sua Jornada Rumo ao Domínio dos Bancos de Dados na Nuvem
Fala galera tech, como vocês estão? espero que bem e codando furiosamente hehe...Então criei esse artigo muito massa, dêem uma lida e claro aquele feedback maroto, e também aproveitei e criei o projeto que detalho no artigo e link do repositório do projeto criado : https://github.com/ArafelD/RDS
Valeu! e boa leitura !!
Imagine por um momento: você está desenvolvendo a próxima aplicação que vai revolucionar o mercado. Sua ideia é brilhante, seu código está impecável, mas há um pequeno detalhe que pode fazer toda a diferença entre o sucesso e o fracasso: onde e como você vai armazenar os dados da sua aplicação?
Se você já passou noites em claro configurando servidores de banco de dados, lidando com backups manuais, ou se perguntando "será que meu banco vai aguentar o pico de acesso?", este artigo é especialmente para você. E se você é novo no mundo do desenvolvimento, prepare-se para descobrir como evitar essas dores de cabeça desde o início!
Ao final desta jornada, você terá uma visão clara de como:
- Transformar ideias em aplicações modernas usando Amazon RDS como base sólida
- Entender a diferença fundamental entre um banco de dados e um serviço de banco de dados
- Dominar os conceitos de sistemas relacionais e consultas SQL de forma prática
- Integrar versionamento com Git & GitHub em projetos de banco de dados
- Aplicar inteligência artificial para otimizar tarefas de banco de dados
- Realizar análises de dados poderosas diretamente do seu RDS
- Construir um projeto Python completo que demonstra todos esses conceitos
🗺️ Estrutura de Projeto Recomendada
Para acompanhar este artigo de forma prática, vamos seguir esta estrutura de projeto:
amazon-rds-project/
├── docs/
│ ├── architecture.md
│ └── database-schema.md
├── src/
│ ├── database/
│ │ ├── connection.py
│ │ ├── models.py
│ │ └── migrations/
│ ├── api/
│ │ ├── app.py
│ │ └── routes/
│ ├── analytics/
│ │ ├── data_analysis.py
│ │ └── ml_integration.py
│ └── utils/
│ ├── git_hooks.py
│ └── ai_helpers.py
├── tests/
├── requirements.txt
├── docker-compose.yml
└── README.md
Mas calma! Antes de mergulharmos no código, vamos entender os fundamentos que tornarão você um verdadeiro mestre dos bancos de dados na nuvem.
🤔 Amazon RDS: Banco de Dados ou Serviço de Banco de Dados? Desvendando o Mistério
A Grande Confusão que Todo Desenvolvedor Já Teve
Você já se perguntou: "O Amazon RDS é um banco de dados ou um serviço que gerencia bancos de dados?" Se sim, você não está sozinho! Esta é uma das perguntas mais frequentes entre desenvolvedores que estão começando a explorar a nuvem AWS.
A resposta é simples e revolucionária: Amazon RDS (Relational Database Service) é um serviço gerenciado de banco de dados, não um banco de dados em si [1]. Pense nele como um "mordomo super inteligente" que cuida de todos os aspectos chatos e complexos de gerenciar bancos de dados para você.
O Que Realmente É o Amazon RDS?
O Amazon RDS é uma plataforma que oferece bancos de dados relacionais como um serviço na nuvem AWS [2]. Ele suporta seis diferentes engines de banco de dados:
- Amazon Aurora (compatível com MySQL e PostgreSQL)
- MySQL
- PostgreSQL
- MariaDB
- Oracle Database
- Microsoft SQL Server
Imagine que você quer abrir um restaurante. Você pode escolher entre:
- Opção A: Comprar todos os equipamentos, contratar chefs, gerenciar estoque, lidar com fornecedores, cuidar da manutenção...
- Opção B: Contratar um serviço completo que já tem tudo pronto e você só precisa focar no seu negócio
O Amazon RDS é a "Opção B" para bancos de dados! Ele elimina as tarefas manuais tediosas como [3]:
- Provisionamento de hardware: Não precisa se preocupar com servidores físicos
- Configuração inicial: O RDS configura automaticamente o banco para você
- Aplicação de patches: Updates de segurança são aplicados automaticamente
- Backups: Backups automáticos diários com retenção configurável
- Monitoramento: Métricas detalhadas de performance em tempo real
- Escalabilidade: Aumento ou diminuição de recursos com poucos cliques
Por Que Isso É Revolucionário?
Antes do RDS, configurar um banco de dados em produção era como montar um quebra-cabeças de 1000 peças... no escuro... com as mãos amarradas! Você precisava:
# O pesadelo do desenvolvedor antes do RDS
1. Provisionar servidor
2. Instalar sistema operacional
3. Configurar rede e segurança
4. Instalar engine do banco de dados
5. Configurar parâmetros de performance
6. Configurar backups
7. Configurar monitoramento
8. Configurar alta disponibilidade
9. Gerenciar patches de segurança
10. Escalar manualmente quando necessário
Com o RDS, isso se resume a:
# A simplicidade do RDS
1. Escolher a engine do banco
2. Definir configurações básicas
3. Clicar em "Launch"
4. Pronto! 🎉
A Analogia Perfeita: RDS como um Hotel 5 Estrelas
Pense no Amazon RDS como um hotel 5 estrelas para seus bancos de dados:
- Você (desenvolvedor) é o hóspede que quer apenas focar no seu trabalho
- Seu banco de dados é você mesmo hospedado no hotel
- O Amazon RDS é toda a infraestrutura do hotel: recepção, limpeza, segurança, manutenção, room service
- Quando você se hospeda em um hotel 5 estrelas, você não se preocupa com:
- Limpeza dos quartos (backups automáticos)
- Segurança do prédio (patches de segurança)
- Manutenção dos elevadores (atualizações de hardware)
- Serviço de quarto (monitoramento 24/7)
Você simplesmente aproveita a estadia e foca no que realmente importa: seu trabalho!
Brainstorm: Questione-se!
Antes de continuarmos, pare um momento e reflita:
- Quanto tempo você já perdeu configurando bancos de dados ao invés de desenvolver features incríveis?
- Quantas vezes você teve que acordar de madrugada porque o banco de dados caiu?
- Qual seria o impacto no seu projeto se você pudesse focar 100% na lógica de negócio?
Se suas respostas foram "muito tempo", "várias vezes" e "seria incrível", então você está pronto para abraçar a revolução do RDS!
📊 Sistemas Relacionais em Banco de Dados: A Espinha Dorsal da Informação
Para entender o Amazon RDS em sua plenitude, é crucial compreender o que são os Sistemas Relacionais em Banco de Dados (SRBDs). Afinal, o 'R' em RDS vem de 'Relational'!
A Lógica por Trás dos Dados Conectados
Um banco de dados relacional é um tipo de banco de dados que armazena e fornece acesso a pontos de dados que estão relacionados entre si [4]. A magia acontece porque os dados são organizados em tabelas, que são compostas por linhas (registros) e colunas (atributos).
Imagine uma planilha gigante, onde cada aba é uma tabela e cada linha é um item único. A grande sacada é que essas tabelas podem se conectar umas às outras através de chaves (primárias e estrangeiras), formando um verdadeiro ecossistema de informações interligadas.
Exemplo:
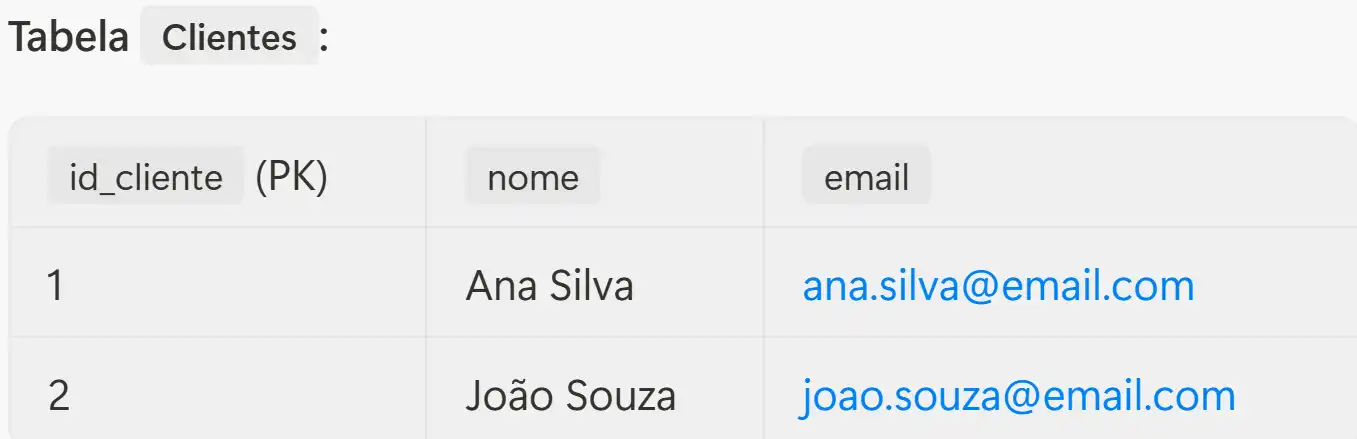
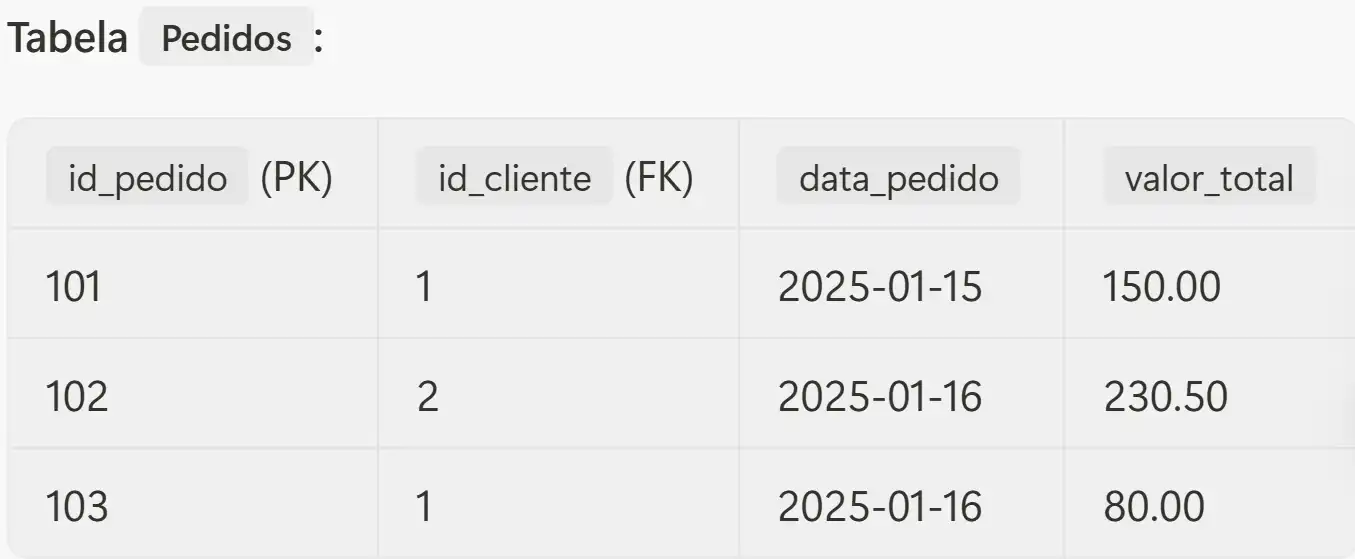
Neste exemplo, a coluna id_cliente na tabela Pedidos é uma chave estrangeira (FK) que se refere à chave primária (PK) id_cliente na tabela Clientes. Isso nos permite saber qual cliente fez qual pedido, sem duplicar informações.
Por Que Relacional é Tão Poderoso?
- Integridade dos Dados: As relações garantem que os dados sejam consistentes e precisos. Se você tentar adicionar um pedido para um id_cliente que não existe, o banco de dados relacional (geralmente) não permitirá.
- Flexibilidade: Você pode combinar dados de diferentes tabelas de diversas maneiras para obter insights complexos.
- Redução de Redundância: Evita a duplicação de dados, economizando espaço e mantendo a consistência.
- Segurança: Permite controlar o acesso a diferentes partes do banco de dados de forma granular.
O Modelo Relacional em Ação
O modelo relacional foi proposto por E.F. Codd em 1970 [5] e se tornou o padrão ouro para a maioria das aplicações de negócios devido à sua robustez e clareza. Ele se baseia em:
- Tabelas: Coleções de dados organizados em linhas e colunas.
- Chaves Primárias (PK): Um identificador único para cada linha em uma tabela.
- Chaves Estrangeiras (FK): Uma coluna em uma tabela que se refere à chave primária de outra tabela, estabelecendo a relação.
- Normalização: Um processo para organizar as colunas e tabelas de um banco de dados relacional para minimizar a redundância de dados e melhorar a integridade dos dados.
Brainstorm: Sua Visão de Dados
- Como você organiza informações no seu dia a dia? Você usa listas, planilhas, notas soltas? Pense em como um sistema relacional poderia trazer ordem a esse caos.
- Se você fosse criar um banco de dados para sua paixão (seja ela culinária, games, filmes), como você estruturaria as tabelas e suas relações? Por exemplo, para filmes: uma tabela para Filmes, outra para Atores, e uma tabela de ligação Filmes_Atores.
Compreender esses fundamentos é o primeiro passo para construir aplicações que não apenas armazenam dados, mas os transformam em conhecimento acionável. E a melhor parte? O Amazon RDS gerencia toda a complexidade da infraestrutura para que você possa focar na modelagem e no uso desses dados!
🔍 Trabalhando com Consultas: A Linguagem Universal dos Dados (SQL)
Se os bancos de dados relacionais são a espinha dorsal da informação, a SQL (Structured Query Language) é a linguagem que nos permite conversar com eles. É através da SQL que você insere, atualiza, exclui e, o mais importante, consulta os dados armazenados no seu Amazon RDS.
SQL: Mais que uma Linguagem, um Superpoder!
Pense na SQL como a chave mestra que abre os tesouros escondidos em seus bancos de dados. Com ela, você pode fazer perguntas complexas e obter respostas precisas em milissegundos. E o melhor: a SQL é padronizada, o que significa que os comandos que você aprende para um banco de dados (como MySQL no RDS) serão muito semelhantes para outros (como PostgreSQL ou SQL Server no RDS).
Os Pilares da SQL: CRUD
Qualquer interação com um banco de dados pode ser resumida em quatro operações básicas, conhecidas como CRUD: Create, Read, Update, Delete.
- CREATE (Criar): Usado para inserir novos registros.
- READ (Ler/Consultar): A operação mais comum, usada para recuperar dados.
- UPDATE (Atualizar): Usado para modificar registros existentes.
- DELETE (Excluir): Usado para remover registros.
Funções Agregadas e Agrupamento: Transformando Dados em Insights
A SQL vai muito além do CRUD. Ela oferece funções poderosas para agregar e agrupar dados, permitindo que você extraia informações valiosas:
- COUNT(): Conta o número de linhas.
- SUM(): Soma os valores de uma coluna.
- AVG(): Calcula a média dos valores de uma coluna.
- MIN(): Encontra o menor valor.
- MAX(): Encontra o maior valor.
SQL
-- Total de pedidos por cliente
SELECT c.nome, COUNT(p.id_pedido) AS total_pedidos
FROM Clientes c
JOIN Pedidos p ON c.id_cliente = p.id_cliente
GROUP BY c.nome
HAVING COUNT(p.id_pedido) > 1;
-- Valor médio dos pedidos
SELECT AVG(valor_total) AS media_valor_pedidos FROM Pedidos;
Brainstorm: O Que Você Perguntaria aos Seus Dados?
Se você tivesse acesso a um banco de dados com informações sobre:
- Seus hábitos de consumo: Quais seriam as 3 perguntas mais interessantes que você faria para entender melhor seus gastos?
- O tráfego da sua cidade: Como você usaria SQL para identificar os horários de pico ou as rotas mais congestionadas?
- As avaliações de um produto online: Que tipo de consulta você faria para encontrar os produtos mais bem avaliados ou as reclamações mais comuns?
Dominar a SQL é como aprender a falar a língua dos seus dados. E com o Amazon RDS, você tem um ambiente otimizado e de alta performance para executar suas consultas, não importa o quão complexas elas sejam.
📈 Análise de Dados com Amazon RDS: Transformando Dados Brutos em Ouro
Ter dados é bom, mas ter insights a partir desses dados é ouro! O Amazon RDS, além de ser um excelente repositório para seus dados transacionais, é também uma plataforma robusta para realizar análises, especialmente quando combinado com outras ferramentas e serviços da AWS.
O RDS como Base para Decisões Inteligentes
Embora o RDS seja otimizado para cargas de trabalho transacionais (OLTP - Online Transaction Processing), ele pode ser a fonte primária para suas análises (OLAP - Online Analytical Processing) em cenários de menor escala ou quando a latência não é um fator crítico. Para análises mais complexas e em larga escala, a AWS oferece serviços dedicados como o Amazon Redshift (Data Warehouse) ou o Amazon Athena (para dados em S3).
No entanto, para muitas aplicações, a análise direta no RDS é perfeitamente viável e eficiente. Você pode usar:
- Consultas SQL Avançadas: Como vimos, a SQL é poderosa. Funções de janela, CTEs (Common Table Expressions) e subconsultas podem extrair insights complexos diretamente do seu banco de dados RDS.
- Ferramentas de BI (Business Intelligence): Conecte ferramentas como o Amazon QuickSight, Tableau, Power BI ou Looker diretamente ao seu RDS para criar dashboards interativos e relatórios visuais. O QuickSight, por exemplo, se integra nativamente com o RDS, facilitando a visualização dos seus dados.
- Linguagens de Programação: Utilize Python (com bibliotecas como Pandas e SQLAlchemy) ou R para conectar-se ao seu RDS, extrair dados, realizar transformações e aplicar modelos estatísticos ou de Machine Learning.
Machine Learning e Inteligência Artificial com RDS
A integração do Amazon RDS com serviços de Machine Learning (ML) e Inteligência Artificial (IA) da AWS abre um universo de possibilidades. Embora o RDS não execute modelos de ML diretamente, ele serve como a fonte de dados para esses modelos.
Exemplos de Integração:
- Amazon SageMaker: Você pode exportar dados do seu RDS para o Amazon S3 e, a partir daí, usar o SageMaker para construir, treinar e implantar modelos de ML. Por exemplo, prever a rotatividade de clientes com base no histórico de compras armazenado no RDS.
- Amazon Aurora ML: Se você usa Amazon Aurora, pode invocar funções de ML diretamente de suas consultas SQL usando o Amazon Aurora ML. Isso permite, por exemplo, detectar anomalias em tempo real ou realizar previsões sem mover os dados para fora do banco [6].
- Amazon Comprehend/Rekognition: Para dados não estruturados (textos, imagens) que podem estar relacionados a dados no seu RDS (e.g., descrições de produtos, avaliações de clientes), você pode usar serviços de IA para processá-los e armazenar os resultados (sentimento, tags, etc.) de volta no RDS para análise.
RDS Performance Insights: Seu Olho no Desempenho
O Amazon RDS Performance Insights é uma ferramenta incrível que ajuda a monitorar e ajustar o desempenho do seu banco de dados [7]. Ele coleta e visualiza métricas de desempenho, permitindo que você identifique gargalos e otimize suas consultas e esquemas para análises mais rápidas.
Brainstorm: O Futuro da Análise de Dados
- Se você pudesse prever algo no seu negócio ou projeto usando dados do seu RDS, o que seria? (Ex: Prever vendas futuras, identificar clientes em risco de churn, otimizar estoque).
- Como a IA poderia automatizar a identificação de padrões nos seus dados? Pense em um assistente de IA que te avisa sobre tendências inesperadas ou anomalias nos seus dados do RDS.
O Amazon RDS não é apenas um local para guardar seus dados; é um trampolim para transformá-los em inteligência acionável, impulsionando a inovação e o crescimento do seu projeto ou negócio. A combinação de dados bem estruturados no RDS com o poder da análise e da IA é uma receita para o sucesso!
🔄 Versionamento com Git & GitHub: O Controle de Versão para o Seu Banco de Dados
Você já versiona seu código-fonte com Git e GitHub, certo? Mas e o seu banco de dados? A verdade é que o esquema do seu banco de dados (tabelas, colunas, índices, stored procedures) também é código e precisa ser versionado! Integrar o versionamento do esquema do banco de dados com seu fluxo de trabalho Git/GitHub é uma prática essencial para equipes de desenvolvimento modernas, especialmente quando se trabalha com um serviço gerenciado como o Amazon RDS.
Por Que Versionar o Esquema do Banco de Dados?
Imagine a seguinte situação: você e sua equipe estão trabalhando em novas funcionalidades. Um desenvolvedor adiciona uma nova coluna, outro altera um tipo de dado, e um terceiro remove uma tabela antiga. Sem um controle de versão adequado, o caos se instala rapidamente. O versionamento do esquema do banco de dados resolve isso, permitindo:
- Rastreabilidade: Saber quem, quando e por que uma alteração foi feita no esquema.
- Colaboração: Múltiplos desenvolvedores podem trabalhar no esquema sem sobrescrever as alterações uns dos outros.
- Reversão: Voltar a uma versão anterior do esquema em caso de problemas.
- Automação: Integrar alterações de esquema em pipelines de CI/CD (Integração Contínua/Entrega Contínua).
Como Versionar o Esquema com Git & GitHub?
Você não vai versionar os dados em si (isso seria impraticável para grandes volumes), mas sim o esquema do banco de dados. As abordagens mais comuns incluem:
- Scripts de Migração: A abordagem mais popular. Você cria pequenos scripts SQL (ou usa ferramentas como Flyway, Liquibase) que representam cada alteração no esquema. Cada script é versionado no Git. Quando você precisa atualizar o banco de dados, você executa esses scripts em ordem.
- Abordagem de Estado Desejado: Ferramentas como SQL Compare (Redgate) ou Schema Compare (Visual Studio) permitem comparar o estado atual do seu banco de dados com um estado desejado (definido em arquivos de script) e gerar um script de sincronização. Os arquivos de script do estado desejado são versionados no Git.
GitFlow para Bancos de Dados
Assim como no código da aplicação, você pode aplicar um fluxo de trabalho Git (como GitFlow) para o esquema do seu banco de dados:
- Branch main (ou master): Representa o esquema do banco de dados em produção.
- Branch develop: Contém o esquema da próxima versão a ser desenvolvida.
- Feature Branches: Para cada nova funcionalidade que requer uma alteração no banco de dados, crie uma feature branch. Desenvolva os scripts de migração nessa branch.
- Pull Requests: Revise as alterações de esquema através de Pull Requests antes de mergear para develop ou main.
Tarefas com IA: O Seu Co-Piloto para o Banco de Dados
A Inteligência Artificial está transformando a forma como interagimos com a tecnologia, e os bancos de dados não são exceção. Embora a IA não vá escrever todo o seu esquema ou suas consultas complexas (ainda!), ela pode ser uma aliada poderosa em diversas tarefas:
- Geração de Consultas SQL: Ferramentas de IA (como o GitHub Copilot, ou modelos de linguagem como o Gemini) podem sugerir ou até mesmo gerar consultas SQL com base em descrições em linguagem natural. Por exemplo, você pode digitar: "selecione todos os clientes que fizeram mais de 5 pedidos no último mês" e a IA pode gerar a consulta SQL correspondente.
- Otimização de Consultas: A IA pode analisar planos de execução de consultas e sugerir índices, reescritas de consultas ou outras otimizações para melhorar o desempenho. Alguns sistemas de gerenciamento de banco de dados já estão incorporando recursos de IA para auto-otimização.
- Modelagem de Dados: Ferramentas de IA podem auxiliar na criação de modelos de dados, sugerindo tabelas, relacionamentos e tipos de dados com base nos requisitos da sua aplicação.
- Detecção de Anomalias: Modelos de ML podem ser treinados para monitorar o comportamento do seu banco de dados (uso de CPU, memória, latência de consultas) e alertar sobre anomalias que podem indicar problemas de desempenho ou segurança.
- Geração de Dados de Teste: A IA pode gerar grandes volumes de dados de teste realistas e consistentes com o esquema do seu banco de dados, o que é crucial para testes de performance e funcionalidade.
- Documentação Automática: Ferramentas de IA podem analisar seu esquema de banco de dados e gerar documentação, dicionários de dados e diagramas, economizando um tempo precioso.
Brainstorm: IA e Você no Comando do Banco de Dados
- Qual tarefa repetitiva no seu dia a dia com bancos de dados você gostaria que a IA automatizasse? (Ex: Criar scripts de backup, gerar relatórios diários, monitorar logs de erro).
- Como a IA poderia te ajudar a aprender SQL mais rápido ou a se tornar um DBA (Administrador de Banco de Dados) melhor? Pense em um tutor de IA que te dá feedback em suas consultas ou te ajuda a depurar problemas.
Lembre-se: a IA é uma ferramenta poderosa em suas mãos. Ela não substitui o seu conhecimento e sua criatividade, mas os amplifica, permitindo que você se concentre em desafios mais complexos e estratégicos. Use-a a seu favor para construir e gerenciar seus bancos de dados no Amazon RDS de forma mais eficiente e inteligente!
💡 Exemplos Práticos e Aplicações Reais: Onde o RDS Brilha de Verdade
Até agora, falamos muito sobre o que é o Amazon RDS e como ele funciona. Mas a verdadeira mágica acontece quando vemos como ele é aplicado no mundo real, impulsionando desde startups inovadoras até gigantes da tecnologia. Prepare-se para se inspirar!
Caso de Uso 1: E-commerce Escalável e Resiliente
Imagine uma loja virtual que precisa lidar com milhares de produtos, milhões de clientes e picos de vendas em datas especiais como a Black Friday. Um banco de dados tradicional em um servidor local seria um pesadelo de gerenciar. Com o Amazon RDS, a história é outra:
- Escalabilidade: Durante a Black Friday, a loja pode escalar sua instância RDS para lidar com o aumento massivo de tráfego e, após o pico, reduzir a escala para economizar custos. Tudo isso com poucos cliques ou de forma automatizada.
- Alta Disponibilidade: Usando o recurso Multi-AZ (Multi-Availability Zone) do RDS, a loja pode ter uma réplica do seu banco de dados em outra zona de disponibilidade. Se a zona principal falhar, o RDS automaticamente faz um failover para a réplica, garantindo que a loja continue online e vendendo, sem interrupções.
- Segurança: Dados sensíveis de clientes e transações são protegidos com criptografia em repouso e em trânsito, além de recursos de segurança de rede da AWS.
Caso de Uso 2: Plataforma de Streaming de Conteúdo
Uma plataforma de streaming precisa armazenar informações sobre filmes, séries, usuários, histórico de visualização, preferências e muito mais. A performance é crucial para garantir uma experiência fluida para o usuário.
•Leitura Otimizada: Com réplicas de leitura (Read Replicas) do RDS, a plataforma pode direcionar as consultas de leitura (como buscar filmes ou histórico de visualização) para essas réplicas, aliviando a carga da instância principal e melhorando a velocidade de resposta para os usuários.
•Gerenciamento Simplificado: A equipe de engenharia pode focar em desenvolver novos recursos e melhorar a experiência do usuário, em vez de se preocupar com a manutenção do banco de dados.
Caso de Uso 3: Aplicações de IoT (Internet das Coisas)
Dispositivos IoT geram um volume massivo de dados em tempo real (sensores de temperatura, medidores de energia, etc.). O Amazon RDS pode ser usado para armazenar e processar esses dados para análises e tomadas de decisão.
- Ingestão de Dados: Dados de milhares de dispositivos podem ser ingeridos no RDS, que é capaz de lidar com altas taxas de inserção.
- Análise em Tempo Real: Com o RDS Performance Insights e integração com serviços de análise, é possível monitorar o desempenho dos dispositivos e identificar padrões ou anomalias quase em tempo real.
Ideias para Agentes Poderosos (e um Pouco de Humor!)
Agora, vamos soltar a imaginação! Como você, um desenvolvedor sagaz, pode usar o Amazon RDS e a IA para construir agentes que realmente fazem a diferença?
- O Agente "Detetive de Dados" 🕵️♀️: Um agente de IA que monitora seu RDS 24/7. Se ele notar uma consulta SQL estranhamente lenta ou um pico incomum de erros, ele não só te avisa, mas também sugere a linha de código exata que está causando o problema e, quem sabe, até um ALTER TABLE para otimizar um índice. Imagine acordar com uma mensagem: "Bom dia! Encontrei um gargalo na sua query get_user_profile. Sugiro criar um índice na coluna last_login_date. Café na conta da casa!" (Ok, talvez o café seja pedir demais, mas a sugestão de otimização é real!)
- O Agente "Arquiteto de Esquemas" 🏗️: Você descreve em linguagem natural o que sua nova funcionalidade precisa armazenar, e o agente de IA, com base nas melhores práticas de modelagem de dados e no seu esquema existente no RDS, sugere a criação de novas tabelas, colunas e relacionamentos. "Preciso de uma tabela para armazenar avaliações de produtos, com nota de 1 a 5 e um campo para comentários." E voilà, o SQL CREATE TABLE aparece na sua tela, pronto para ser revisado.
- O Agente "Historiador de Dados" 📜: Integrado ao seu Git/GitHub, este agente monitora as migrações de banco de dados. Se uma migração falhar em produção, ele automaticamente reverte o esquema para a versão anterior e te envia um relatório detalhado do que deu errado, com links para a linha exata no seu repositório Git. "Migração V1.5 falhou. Rollback concluído. Erro na linha 27 do V1.5__add_new_feature.sql. Parece que você esqueceu um COMMIT!" (Acontece nas melhores famílias de devs!)
Brainstorm: Sua Próxima Grande Ideia
- Qual problema do seu dia a dia (pessoal ou profissional) poderia ser resolvido com uma aplicação que usa um banco de dados relacional na nuvem? Pense em algo que você gostaria de organizar, rastrear ou analisar.
- Como você usaria a IA para tornar essa aplicação ainda mais inteligente e útil? Seria um chatbot que interage com o banco de dados? Um sistema de recomendação? Um assistente de automação?
O Amazon RDS não é apenas uma ferramenta; é um catalisador para a inovação. Ele liberta você das preocupações com a infraestrutura, permitindo que sua criatividade e suas ideias de agentes poderosos ganhem vida. O limite é a sua imaginação!
🧩 Entendendo o Projeto Amazon RDS para Não-Desenvolvedores (Low-Code/No-Code)
Se você não é um desenvolvedor, mas quer entender como funciona um projeto de software que usa um banco de dados na nuvem, este guia é para você! Vamos simplificar o projeto que criamos e mostrar como ele se encaixa no mundo real, mesmo sem escrever uma linha de código.
🏠 A Casa do Nosso Projeto: O que Cada Parte Faz?
Pense no nosso projeto como uma casa bem organizada, onde cada cômodo tem uma função específica:
amazon-rds-project/
├── src/ # Onde a 'mágica' acontece: o coração da casa
│ ├── database/ # A 'Despensa' e o 'Caderno de Receitas' do Banco de Dados
│ │ ├── connection.py # A 'Tomada' que liga na nuvem (AWS RDS)
│ │ ├── models.py # O 'Cardápio' com todos os pratos (dados) que servimos
│ │ └── migrations/ # O 'Diário de Reformas' da despensa
│ ├── api/ # A 'Cozinha' que prepara e serve os pedidos
│ │ ├── app.py # O 'Chef Principal' que coordena tudo
│ │ └── routes/ # As 'Mesas' onde os pedidos são entregues
│ ├── analytics/ # O 'Escritório de Análise' que entende o que está acontecendo
│ │ ├── data_analysis.py # O 'Contador' que faz relatórios de vendas
│ │ └── ml_integration.py# O 'Vidente' que prevê o futuro e segmenta clientes
│ └── utils/ # A 'Caixa de Ferramentas' com ajudantes especiais
│ ├── git_hooks.py # O 'Guarda-Livros' que anota cada mudança
│ └── ai_helpers.py # O 'Assistente Inteligente' que ajuda nas tarefas
├── docs/ # A 'Biblioteca' com todos os manuais
├── tests/ # A 'Área de Testes' para garantir que tudo funciona
├── requirements.txt # A 'Lista de Compras' para a casa funcionar
└── README.md # O 'Manual de Instruções' da casa
Detalhando os Cômodos (e suas Funções Low-Code/No-Code):
📦 src/database/ - A Despensa e o Caderno de Receitas do Banco de Dados
- connection.py (A Tomada que liga na nuvem): Imagine que seu banco de dados está guardado em um cofre super seguro na nuvem da Amazon (o Amazon RDS). Este arquivo é como a tomada que conecta sua casa a esse cofre. Ele sabe o endereço, a senha e como falar com o cofre para pegar ou guardar informações. Sem ele, nada funciona!
- models.py (O Cardápio com todos os pratos): Aqui, nós descrevemos o que vamos guardar no nosso cofre. Por exemplo, se temos uma loja, vamos guardar informações de Clientes (nome, e-mail), Produtos (nome, preço) e Pedidos (quem comprou o quê). É como um cardápio que diz: "Temos pratos de cliente, pratos de produto e pratos de pedido, e eles se conectam assim".
- migrations/ (O Diário de Reformas da despensa): Conforme sua loja cresce, você pode precisar adicionar um novo tipo de informação (por exemplo, o telefone do cliente). Este diretório guarda um diário de todas as "reformas" que fizemos no nosso cofre de dados. Cada arquivo aqui é uma instrução para o cofre: "Adicione um campo para telefone na ficha do cliente". Isso garante que todos os cofres (de desenvolvimento, de testes, de produção) estejam sempre iguais.
🍳 src/api/ - A Cozinha que Prepara e Serve os Pedidos
- app.py (O Chef Principal): Este é o cérebro da nossa cozinha. Ele recebe os pedidos de fora (por exemplo, "Quero ver a lista de clientes" ou "Quero cadastrar um novo produto"), vai até a despensa (banco de dados), pega ou guarda o que precisa, e prepara a resposta para quem pediu. É ele quem faz a comunicação entre o mundo exterior e o nosso cofre de dados.
- routes/ (As Mesas onde os pedidos são entregues): Pense nas rotas como as mesas do restaurante. Cada mesa tem um número e um tipo de pedido que pode ser feito lá. Por exemplo, a "mesa /clientes" é onde você pode pedir a lista de clientes ou cadastrar um novo. O chef (app.py) sabe exatamente para qual mesa direcionar cada pedido.
📊 src/analytics/ - O Escritório de Análise
•data_analysis.py (O Contador que faz relatórios de vendas): Este é o nosso contador particular. Ele entra na despensa (banco de dados), pega todos os dados de vendas, clientes e produtos, e transforma em relatórios fáceis de entender. Por exemplo: "Quantas vendas tivemos no último mês?", "Qual produto vendeu mais?". Ele te dá a visão geral do seu negócio.
- ml_integration.py (O Vidente que prevê o futuro e segmenta clientes): Este é o nosso "vidente" e "organizador" de clientes. Ele usa técnicas avançadas (Machine Learning) para:
- Prever vendas futuras: Com base no histórico, ele tenta adivinhar quanto você vai vender na próxima semana.
- Segmentar clientes: Ele agrupa seus clientes em categorias (ex: "Clientes VIP", "Clientes Novos", "Clientes Sumidos") para que você possa criar estratégias específicas para cada grupo.
🛠️ src/utils/ - A Caixa de Ferramentas com Ajudantes Especiais
- git_hooks.py (O Guarda-Livros que anota cada mudança): Este ajudante é super importante para manter a organização. Ele garante que cada "reforma" na despensa (banco de dados) seja devidamente anotada e guardada em um histórico (o Git e GitHub). Assim, se algo der errado, sabemos exatamente o que mudou e podemos voltar atrás.
- ai_helpers.py (O Assistente Inteligente que ajuda nas tarefas): Este é o seu assistente pessoal de IA para o banco de dados. Ele pode:
- Traduzir pedidos: Você fala em português ("Quero ver os 10 produtos mais caros") e ele traduz para a linguagem do cofre (SQL).
- Otimizar: Ele olha para as instruções que você deu ao cofre e sugere como fazê-las mais rápido.
- Criar dados de teste: Ele inventa dados falsos, mas realistas, para você testar sua loja sem usar dados de verdade.
📚 docs/ - A Biblioteca com Todos os Manuais
Aqui ficam todos os documentos importantes do projeto: como a casa foi construída, como o banco de dados funciona, guias de uso, etc.
🧪 tests/ - A Área de Testes
Antes de abrir a casa para o público, precisamos ter certeza de que tudo funciona perfeitamente. Esta área é onde fazemos todos os testes: as torneiras funcionam? A luz acende? Os pedidos chegam na cozinha?
🛒 requirements.txt - A Lista de Compras
Para que a casa funcione, precisamos de alguns "ingredientes" e "ferramentas" básicas (programas e bibliotecas). Esta lista garante que temos tudo o que precisamos instalado.
📖 README.md - O Manual de Instruções da Casa
Este é o primeiro documento que você lê. Ele explica o que é a casa, como ela funciona, como ligar a energia, como usar a cozinha, etc. É o guia completo para qualquer um que queira entender ou usar o projeto.
🚀 Como Isso Ajuda Quem Não é Desenvolvedor?
Mesmo sem escrever código, entender essa estrutura te dá o poder de:
- Comunicar-se melhor: Você pode conversar com desenvolvedores e entender o que eles estão fazendo e por que.
- Tomar decisões: Se você sabe onde os dados estão e como são analisados, pode pedir relatórios específicos ou sugerir novas análises para o seu negócio.
- Visualizar o processo: Compreender o fluxo de dados e as responsabilidades de cada parte do sistema.
- Usar ferramentas Low-Code/No-Code: Muitas ferramentas visuais (como o Power BI para análise, ou plataformas de automação como Zapier) se conectam a esses "cômodos" do projeto. Você pode, por exemplo, usar uma ferramenta no-code para criar um painel visual que mostra as vendas diárias, puxando os dados do nosso "Escritório de Análise" que, por sua vez, pegou os dados do "Cofre RDS"!
O objetivo é desmistificar a tecnologia e mostrar que, por trás de códigos complexos, existem lógicas e estruturas que podem ser compreendidas por todos. E com o Amazon RDS, essa complexidade de infraestrutura é ainda mais simplificada, permitindo que você foque no que realmente importa: sua ideia e seu negócio!
🌟 Conclusão: O Futuro é Agora, e Ele é Gerenciado!
Chegamos ao fim da nossa jornada pelo universo do Amazon RDS, e espero que você tenha percebido o quão transformador esse serviço pode ser para sua carreira e seus projetos. Longe de ser apenas um "banco de dados na nuvem", o RDS é um parceiro estratégico que automatiza as tarefas mais tediosas, libera seu tempo e permite que você se concentre no que realmente importa: criar valor e inovar.
Recapitulando, vimos que o Amazon RDS:
- É um serviço gerenciado que cuida da infraestrutura do banco de dados para você.
- Permite que você utilize os principais engines de bancos de dados relacionais (MySQL, PostgreSQL, Aurora, etc.).
- Simplifica a escalabilidade, alta disponibilidade e segurança dos seus dados.
- É a base para análises de dados poderosas e integrações com Inteligência Artificial.
- Se beneficia enormemente do versionamento de esquema com Git & GitHub, garantindo um fluxo de trabalho moderno e colaborativo.
O Chamado à Ação: Não Fique Para Trás!
O mundo da tecnologia avança a passos largos, e a capacidade de gerenciar e utilizar dados de forma eficiente é uma habilidade cada vez mais valiosa. O Amazon RDS é uma ferramenta fundamental nesse cenário, e dominá-lo é um diferencial competitivo.
Meu desafio para você:
- Experimente! Crie uma conta gratuita na AWS (se ainda não tiver) e provisione sua primeira instância RDS. Comece com um banco de dados pequeno, explore o console, faça algumas consultas. A prática leva à perfeição!
- Continue Aprendendo! O universo da AWS é vasto. Explore outros serviços que se integram com o RDS, como o Amazon S3 para armazenamento de objetos, o AWS Lambda para funções serverless, e o Amazon QuickSight para visualização de dados.
- Inove com IA! Pense em como você pode usar as ferramentas de IA que discutimos para otimizar suas tarefas diárias com bancos de dados. Seja para gerar SQL, otimizar consultas ou até mesmo para criar um "agente detetive de dados" pessoal.
Lembre-se, a tecnologia está aqui para nos servir. O Amazon RDS é um exemplo brilhante de como a nuvem pode simplificar complexidades, permitindo que desenvolvedores como você construam aplicações mais robustas, escaláveis e inteligentes. O futuro é agora, e ele é gerenciado. Que tal começar a construir o seu hoje?
📚 Referências:
[1] O que é o Amazon Relational Database Service (Amazon RDS)? - AWS Documentation. Disponível em: https://docs.aws.amazon.com/pt_br/AmazonRDS/latest/UserGuide/Welcome.html
[2] AWS RDS (Relational Database Service) - Amazon Web Services. Disponível em: https://aws.amazon.com/pt/rds/
[3] Perguntas frequentes sobre o Amazon RDS | Banco de dados relacional na nuvem - AWS. Disponível em: https://aws.amazon.com/pt/rds/faqs/
[4] O que é um banco de dados relacional (RDBMS)? | Google Cloud. Disponível em: https://cloud.google.com/learn/what-is-a-relational-database?hl=pt-BR
[5] Codd, E. F. (1970). A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, 13(6), 377-387. (Referência conceitual, buscar por artigo ou resumo online)
[6] Using Amazon Aurora machine learning - AWS Documentation. Disponível em: https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-ml.html
[7] Insights de Performance do Amazon RDS | Cloud Relational Database - AWS. Disponível em: https://aws.amazon.com/pt/rds/performance-insights/



